让人工智能更理解物理世界!中国人民大学、北京邮电大学和上海AI实验室等机构提出了一种新的多模态分割方法。
编辑日期:2024年08月30日
相关数据集和代码已经开源。
让AI像人类一样利用多模态线索定位感兴趣的物体,有了新的方法!
相关论文已被顶级会议ECCV 2024接收。

举个例子,在下面这张图中,机器如何准确识别出正在演奏乐器的人?
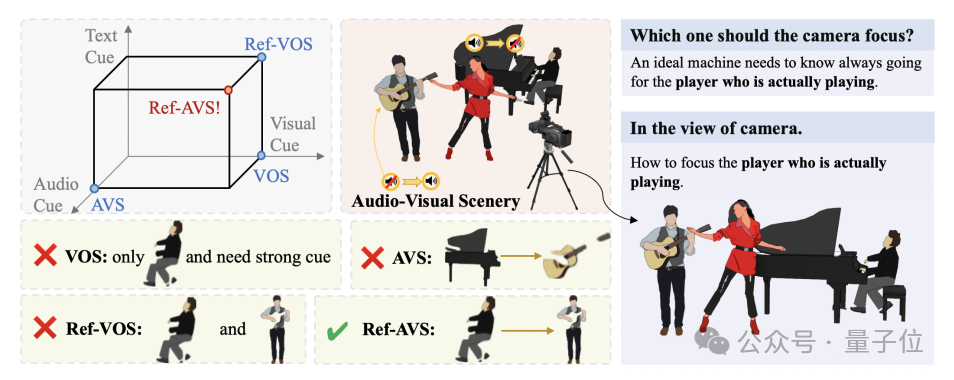
单靠一种模态显然不够,但现有研究往往分别从视觉、文本和音频角度进行探索。
而新方法Ref-AVS则整合了文本、音频和视觉等多个模态的关系,以适应更真实的动态视听场景。
这样一来,即使是同时在唱歌和弹吉他的人都能被轻松识别出来。

同一段素材还可以反复利用,找到正在发声的吉他也不成问题。

此外,研究人员还构建了一个名为Ref-AVS Bench的数据集,并设计了一个端到端框架来高效处理多模态线索。
具体细节如下:
总体来说,数据集Ref-AVS Bench包含了40020个视频帧,涉及6888个物体和20261个指代表达式(Reference Expression)。
每个数据点都包含与视频帧对应的音频,并提供了逐帧的像素级标注。
为了确保所指代对象的多样性,团队选择了包含背景在内的52个类别,其中48个是可发声物体类别,另外3个是静态、不可发声物体类别。
在视频收集过程中,所有视频均来自YouTube,并截取为10秒片段。
在整个手动收集过程中,团队特意排除了以下几种类型的视频:a) 含有大量重复语义实例的视频;b) 编辑过多且频繁切换镜头视角的视频;c) 非现实的合成视频。为了更好地匹配真实世界的分布,团队选择了有助于增加数据集场景多样性的视频,特别是那些涉及多个对象(如乐器、人物、车辆等)互动的视频。
此外,表达式(Expression)的多样性是Ref-AVS数据集构建的重要组成部分。除了文本语义信息外,表达式还涵盖了听觉、视觉和时间三个维度的信息。听觉维度包括音量、节奏等特征,视觉维度则包括物体的外观和空间属性。团队还利用时间线索生成带有时序提示的引用,例如“先发出声音的物体”或“后出现的物体”。通过整合听觉、视觉和时间信息,研究人员设计出了丰富的表达式,不仅能够准确反映多模态场景,还能满足用户对精确引用的具体需求。
表达式的准确性也是研究中的核心关注点。为此,研究团队遵循以下三个规则来生成高质量的表达式: 1)唯一性:每个表达式所指的对象必须明确且唯一,不能同时指向多个对象。 2)必要性:虽然可以使用复杂的表达式来指代对象,但句子中的每个形容词都应有助于缩小目标对象的范围,避免不必要的冗余描述。 3)清晰度:某些表达模板可能带有主观因素,例如“声音更大的__”,这类表达仅在情况足够清晰时使用,以避免歧义。
团队还将每段10秒的视频分成十个相等的1秒片段,并利用Grounding SAM对这些片段进行分割和标记,之后要求标注员手动检查并修正这些关键帧。
此过程使团队能够在关键帧内为多个目标对象生成掩码和标签。确定了关键帧的掩码后,团队会应用跟踪算法来追踪这些目标对象,并在10秒的时间范围内获得最终的真实掩码标签(Ground Truth Mask)。
在数据分割与统计阶段,测试集中的视频及其对应的注释将由经过培训的标注人员进行细致审查和校正。
为了全面评估模型在Ref-AVS任务中的表现,测试集被进一步划分为三个不同的子集。
具体来说,这三个测试子集包括:
完成数据集准备后,团队采用多模态线索增强表达式指代能力(Expression Enhancing with Multimodal Cues, EEMC),以实现更精准的视听指代分割。
具体而言,在时序双模态融合(Temporal Bi-Modal Transformer)模块中,团队将包含时序信息的视听模态信息(FV, FA)分别与文本信息(FT)融合。
为了使模型更好地感知时序信息,研究提出了一个直观的缓存记忆机制(Cached Memory Mechanism, CV, CA)。
缓存记忆机制需要存储从起始到当前时刻的时序平均模态特征,以捕捉时序变化中多模态信息的变化幅度。多模态特征(QV, QA)的计算方式如下:
其中, 表示时序中的特定时间步, 是一个可调节的超参数,用于控制模型在时序过程中对特征变化的敏感度。
当当前的音频或视觉特征与过去的特征平均值相差不大时,输出的特征基本保持不变。然而,当这种变化较为显著时,cached memory能够放大当前特征的差异,从而生成具有显著特征的输出。
随后,拼接的多模态特征被输入到Multimodal Integration Transformer模块中进行多模态融合,生成包含多模态信息的指示表达最终特征(QM),作为掩码解码器的输入。
掩码解码器是基于Transformer架构的分割基础模型,例如MaskFormer、Mask2Former或SAM。
研究团队选择了Mask2Former作为分割基础模型,利用其预训练的mask queries,以及多模态指代表达特征。通过一个交叉注意力Transformer(CATF),将多模态指代表达特征迁移到mask queries中,从而使分割基础模型可以根据多模态特征进行分割。
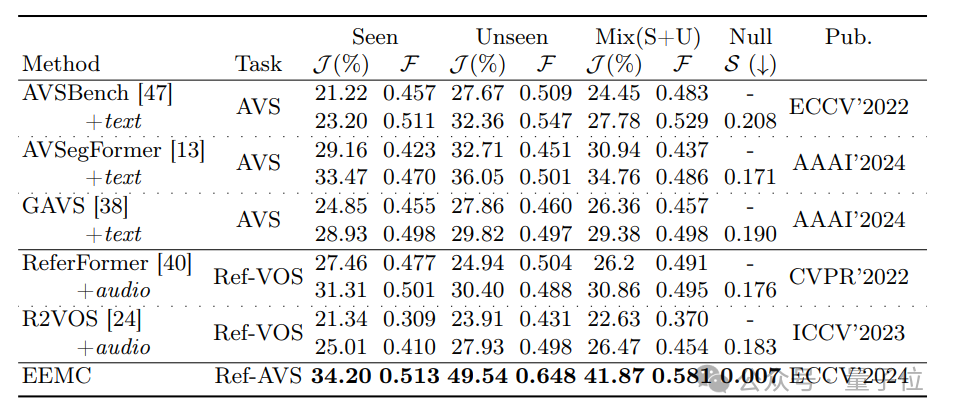
在定量实验中,团队将所提出的方法与其他方法进行了对比,并为其他方法补充了缺失的模态信息以确保公平性。测试结果表明,在Seen子集上,新方法Ref-AVS的表现优于其他方法。同时,在Unseen子集和Null子集上,Ref-AVS展示了良好的泛化能力,并能准确地跟随指代表达。
在定性实验中,团队在Ref-AVS Bench测试集上对分割掩码进行了可视化,并与AVSegFormer和ReferFormer进行了比较。

结果显示,ReferFormer在Ref-VOS任务中的表现以及AVSegFormer在AVS任务中的表现均未能准确分割出表达中描述的对象。具体来说,AVSegFormer在理解表达时遇到困难,往往会直接生成声音源。
例如,在左下角的样本中,AVSegFormer错误地将吸尘器分割为目标对象,而不是男孩。
另一方面,Ref-VOS可能无法充分理解音频-视觉场景,因此误将幼童识别为钢琴演奏者,如右上角的样本所示。
相比之下,Ref-AVS方法展现出了更出色的能力,能够同时处理多模态表达和场景,从而准确理解用户指令并分割出目标对象。
未来的研究可以考虑采用更优质的多模态融合技术、提高模型应用的实时性,并扩展和多样化数据集,以便将多模态指代分割技术应用于视频分析、医疗图像处理、自动驾驶和机器人导航等挑战中。
更多详情欢迎查阅原论文。