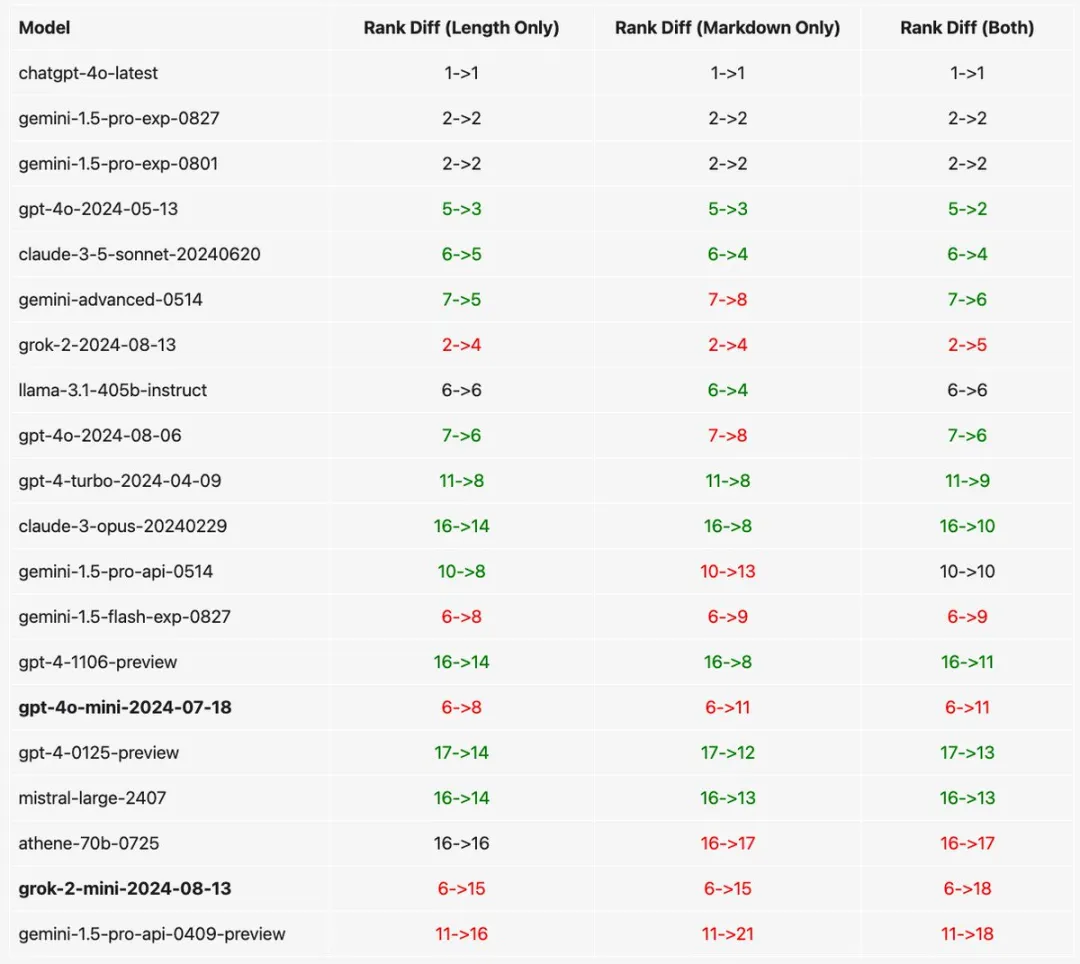
GPT-4迷你版的排名急剧下滑,大型模型竞技场的规则进行了更新,导致奥特曼刷分的小技巧失效了。
编辑日期:2024年09月02日
分数更真实地反映了模型的能力,而非风格。
在大模型竞技场规则更新后,GPT-4o mini的排名迅速下滑,跌出了前十名。

新榜单降低了对AI回答长度和风格等因素的权重,确保分数能够准确反映模型解决问题的能力。
过去那些依靠美观的格式和增加小标题数量来吸引用户、提升排名的做法,现在已不再奏效。
在新的规则下,奥特曼的GPT-4o mini、马斯克的Grok-2系列以及谷歌的Gemini-1.5-flash小模型排名均显著下降。而Claude系列和Llama-3.1-405b大模型的得分则有所上升。
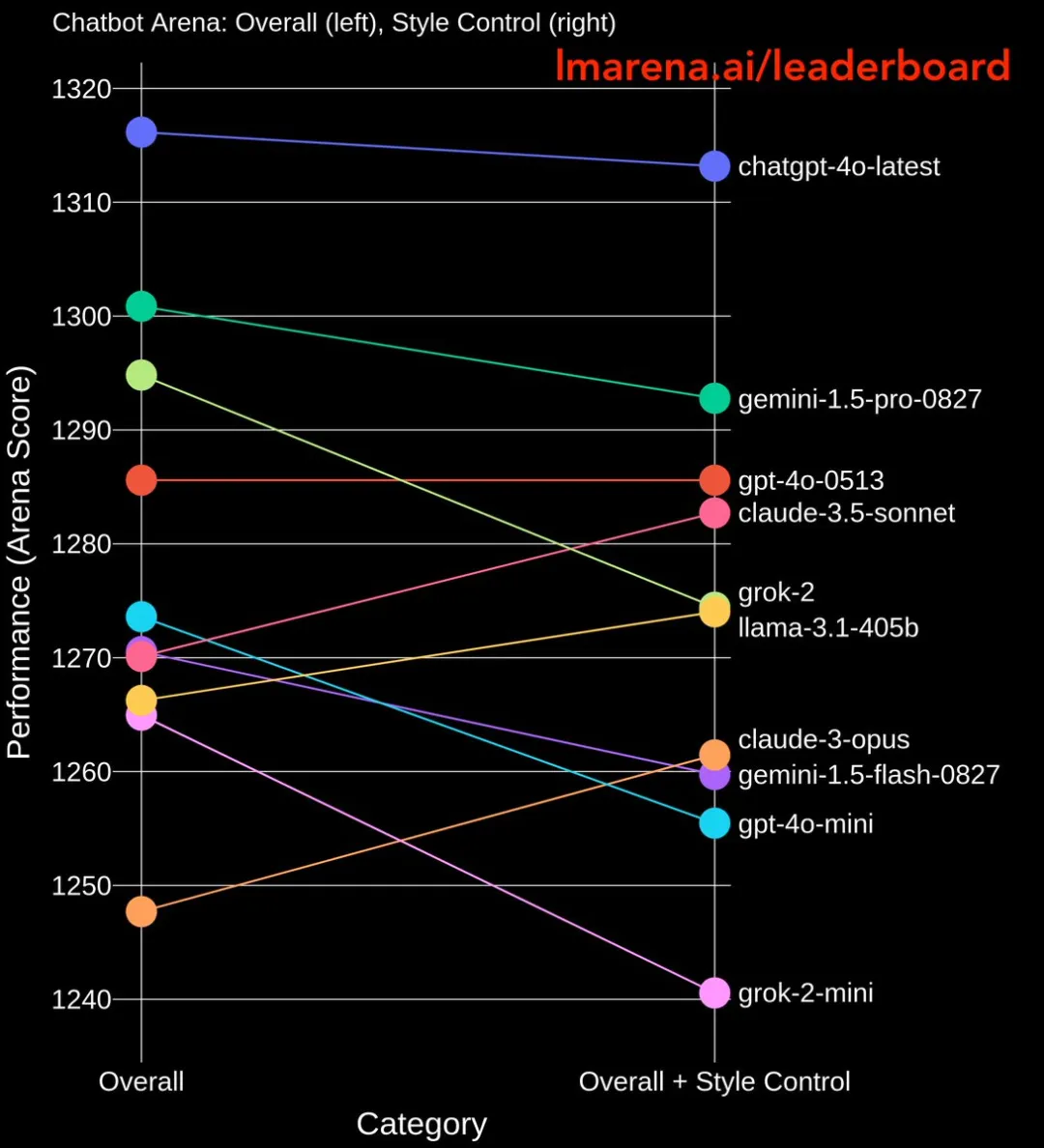
在仅计算困难任务(Hard Prompt)的情况下,大模型在风格控制方面的优势更为明显。
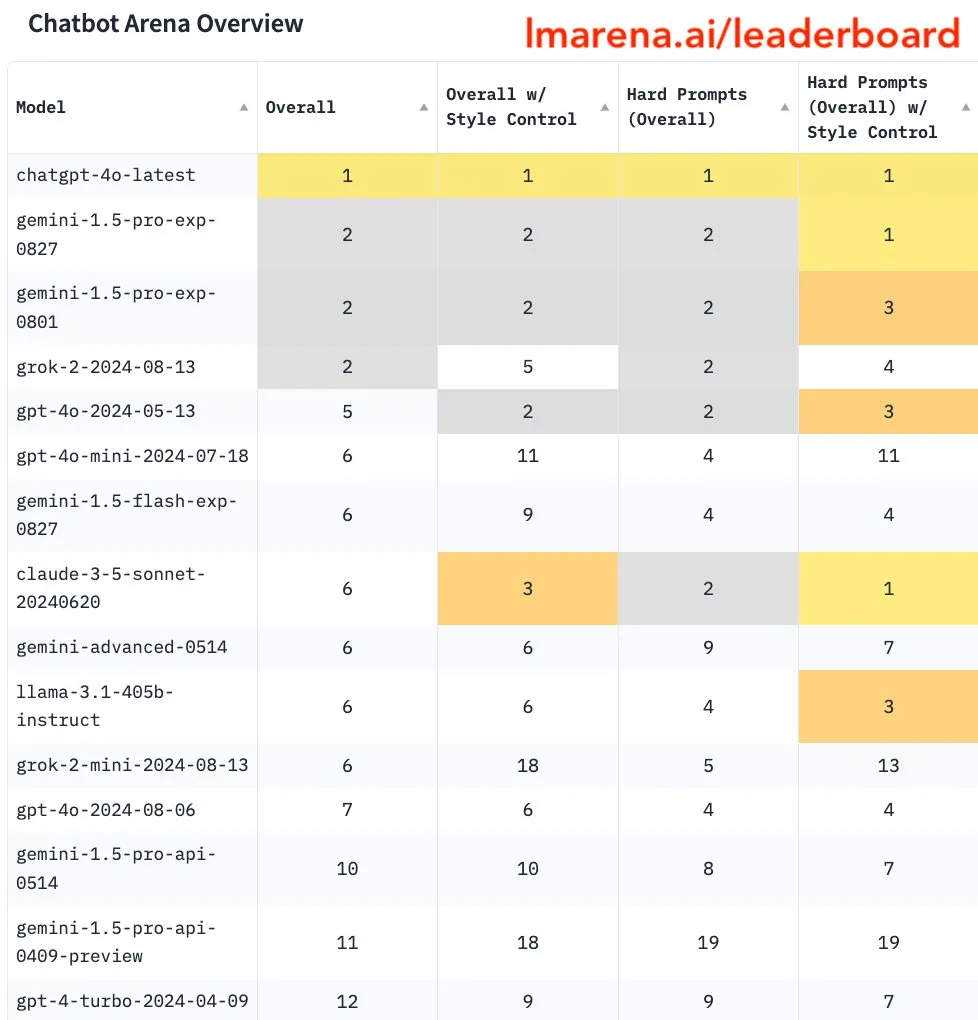
此前,GPT-4o mini小模型曾一度登顶,并与GPT-4o满血版并列第一,这与用户的实际体验并不相符。
Lmsys大模型竞技场这一曾被Karpathy推荐的评价标准,其口碑也因此跌至“只能反映用户喜好,而非模型能力”的境地。
为了改进这一情况,Lmsys组织公开了GPT-4o mini参与的1000场对决数据,分析得出模型拒绝回答率、生成内容长度及格式排版是影响投票结果的关键因素。
此外,奥特曼在GPT-4o mini发布前也曾暗示,该模型是根据人类偏好进行优化的。
现在,Lmsys进一步推出了一种新的算法来控制这些因素,并且这只是其规划的第一步。
假设有一个模型A,它擅长生成代码、事实和无偏见的答案等,但输出非常简洁;而另一个模型B,在实质内容(例如正确性)方面表现不佳,但其输出内容长而详细、格式排版华丽。那么,哪个模型更好呢?
答案并非唯一。Lmsys尝试通过数学方法来确定一个模型的得分中有多少是由内容或风格贡献的。
最近的研究表明,人们可能更偏好那些排版漂亮且内容详细的AI回答。
为了实现这一目标,研究人员在Bradley-Terry回归中增加了样式特征,如响应长度、Markdown小标题的数量、列表和加粗文本的数量作为自变量。这是一种常用的统计技术,最近被AlpacaEval LC等用于大规模模型的评估。
在回归分析中加入任何混杂变量(例如回答长度),可能会将评分的提升归因于这些混杂变量,而非模型自身的能力。
相关代码已经在Google Colab上公开。此外,研究团队还进行了“仅控制长度”和“仅控制格式”的消融实验,发现GPT-4o mini和谷歌Gemini系列模型的分数受格式的影响更大。
然而,这种方法也有局限性,例如可能存在未观察到的混杂因素,如长度与回答质量之间的正相关关系,这些因素尚未被考虑在内(例如思维链提示)。
不少网友表示,调整后的困难任务排行榜与他们的主观印象更加一致。


GPT-4迷你版的排名急剧下滑,大型模型的表现引起了广泛关注。一些人认为,正是由于榜单上各大模型公司的不断竞争,整个领域才能够共同进步。
你还在根据大模型竞技场的结果来选择模型吗?或者是否有更好的评估方法?欢迎在评论区分享你的见解。
参考链接: [1] https://x.com/lmsysorg/status/1829216988021043645 [2] https://lmsys.org/blog/2024-08-28-style-control/ [3] https://arxiv.org/abs/2402.10669
西湖大学MiLab负责人王东林牵头了相关研究工作。
荣耀公司也同步发布了其AI战略。
此外,还有一种方法是利用“小”算法来辅助“大”模型。
某些模型甚至能够实现超快速地从1数到100。
更有甚者,不同规模的模型已经实现了全面开源。
 包括评估“AI自我复制、逃出实验室”的风险
包括评估“AI自我复制、逃出实验室”的风险
重写为:
包括评估“AI自我复制和逃离实验室”的风险。