








谷歌 AI 推出 CardBench 评估框架:包含 20 个真实数据库,以更全面地评估基数估计模型
编辑日期:2024年09月03日
CardBench 基准是一个综合评估框架,包含了来自 20 个不同真实数据库的数千条查询,其规模远超以往的任何基准测试。
基数估算(cardinality estimation,简称 CE)是优化关系数据库查询性能的关键环节,它涉及预测数据库查询将返回的中间结果数量,直接关系到查询优化器对执行计划的选择。
准确的卡入度估计对于选择高效的连接顺序、决定是否使用索引以及选择最佳连接方法来说至关重要。
这些决策将对查询执行时间和数据库的整体性能产生重大影响。不准确的估计会导致不佳的执行计划,从而大幅降低性能,有时甚至会使其下降几个数量级。
现代数据库系统中广泛采用的基数估算技术,依赖于启发式方法和简化模型,例如假设数据均匀分布和列之间相互独立。
这些方法虽然计算效率很高,但通常需要精确预测基数,在处理涉及多个表格和过滤器的复杂查询时,这一缺点尤为明显。
最新的数据驱动方法旨在不执行查询的情况下,对表内和表间的数据分布进行建模,从而减少了一部分开销。然而,当数据发生变化时,仍然需要重新进行训练。
尽管取得了这些进展,但由于缺乏全面的基准,很难对不同模型进行比较,也难以评估它们在各种数据集上的通用性。
CardBench 可以在各种条件下对学习到的基数模型进行更全面的评估。该基准支持以下三种关键设置:
该基准测试提供了两组训练数据:一组用于包含多个筛选条件谓词的单表查询,另一组用于涉及两个表的二元连接查询。
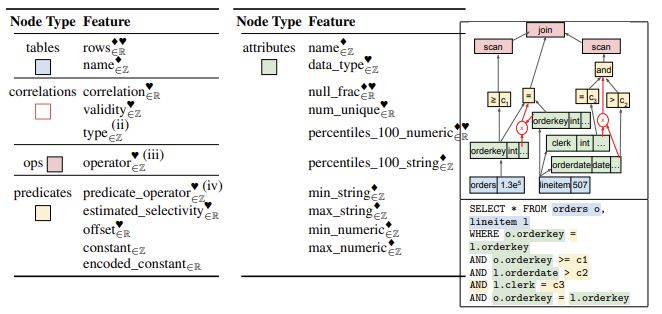
该基准测试包含 9125 个单表查询和 8454 个二元连接查询,适用于其中一个小规模的数据集,从而确保为模型评估提供一个强大且富有挑战性的环境。
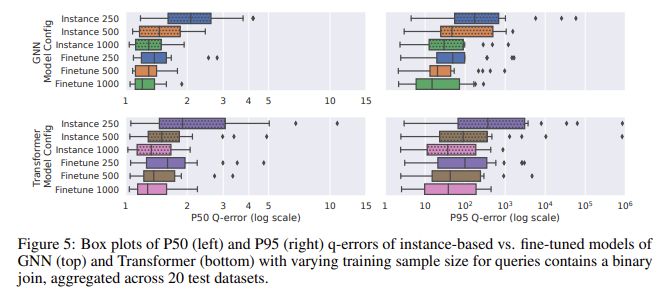
例如,对图神经网络(GNN)模型进行微调后,在二进制连接查询中的 q-error 中位数为 1.32,第 95 百分位数为 120,明显优于未微调的模型。这表明,即使在进行了 500 次查询的情况下,对预训练模型进行微调也能显著提升其性能,使其在训练数据有限的实际应用中变得更加可行。
总之,CardBench 在学习基数估计方面取得了重大进展。通过提供一个全面且多样化的基准,研究人员可以系统地评估和比较不同的 CE 模型,从而推动这一关键领域内的进一步创新。该基准支持那些需要较少数据和训练时间的微调模型,为训练新模型成本过高的实际应用提供了切实可行的解决方案。
请提供参考地址。 (如果是要重写"附上参考地址"这句话,是否需要更具体的上下文信息呢?)


















