








谷歌 DeepMind 展示 GenRM 技术:通过微调大型语言模型作为奖励模型,提升生成式 AI 的推理能力
编辑日期:2024年09月03日
在人工智能行业,目前提升大型语言模型(LLMs)性能的主流方法是Best-of-N模式,即由LLM生成N个候选答案,然后通过验证器对这些答案进行排序并选择最优解。
这种基于大型语言模型(LLM)的验证器通常被训练成判别分类器来为解决方案评分,但它们无法利用预训练的大型语言模型的文本生成能力。
为了解决这一局限性,DeepMind团队尝试通过预测下一个token来训练验证器,并同时进行验证和解决方案的生成。
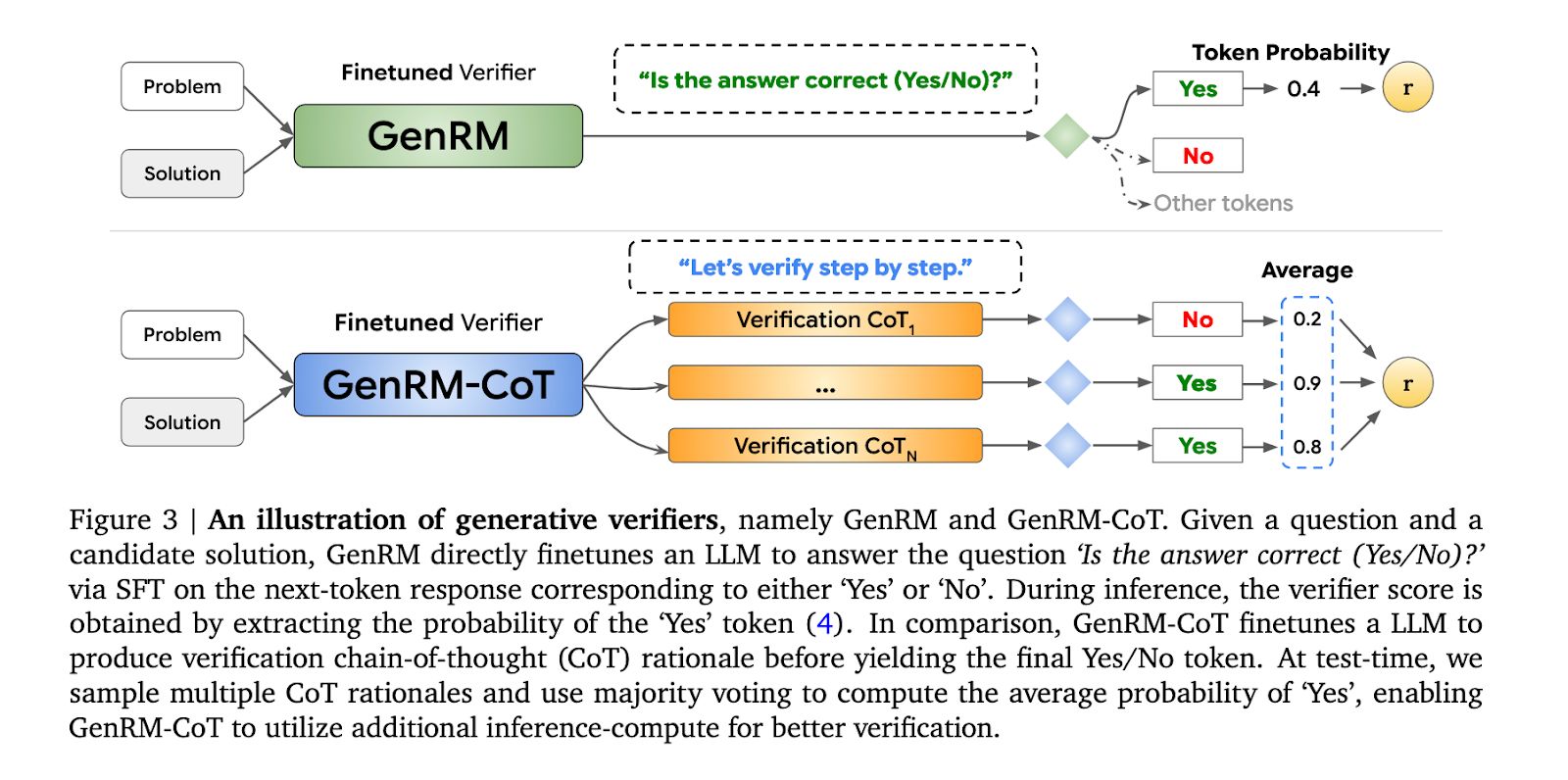
DeepMind 团队开发的生成式验证器(GenRM)相较于传统验证器,主要具有以下优点:
在算法和小学数学推理任务中,当使用基于Gemma的验证器时,GenRM的表现优于判别式验证器和LLM-as-a-Judge验证器,解决问题的Best-of-N使用率提高了16-64%。
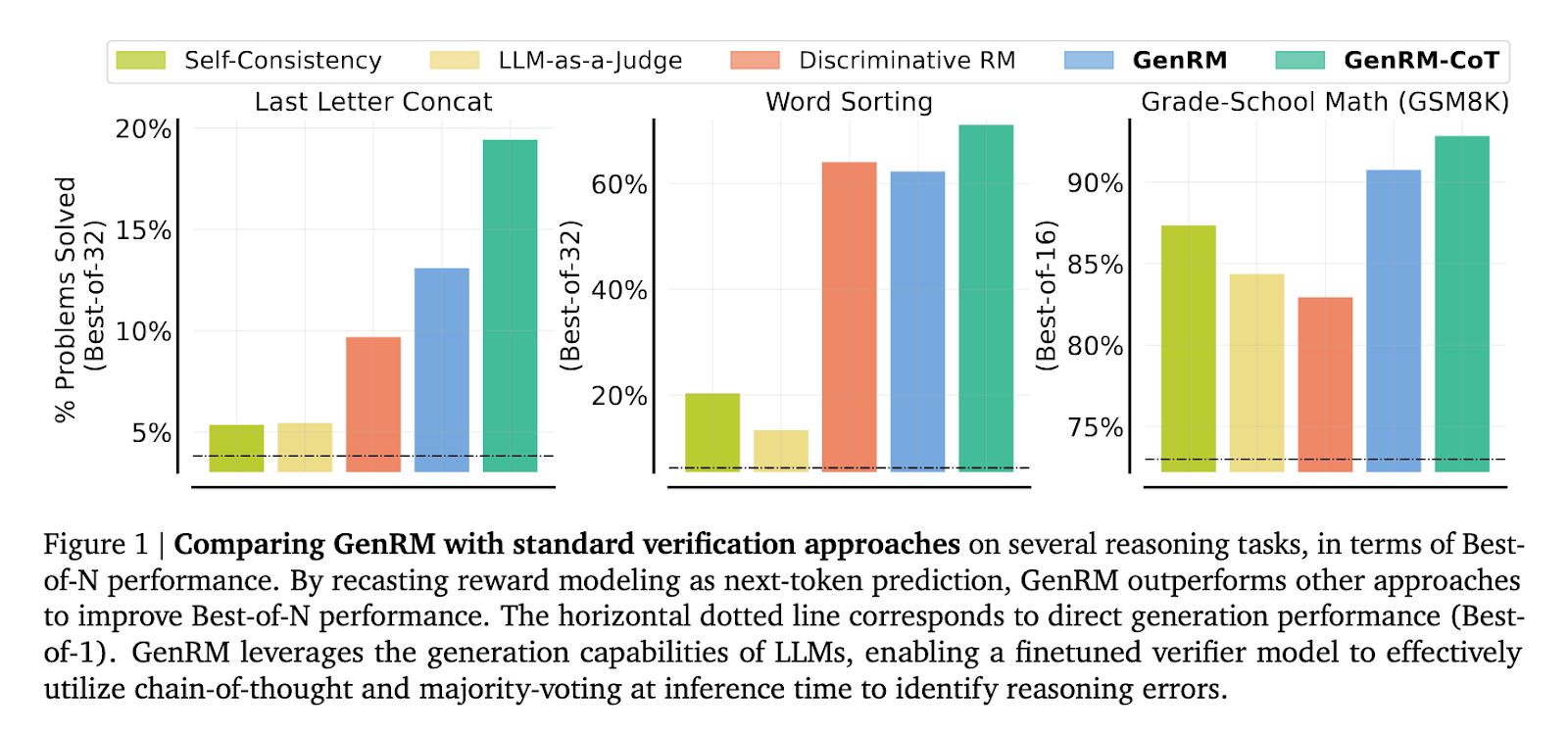
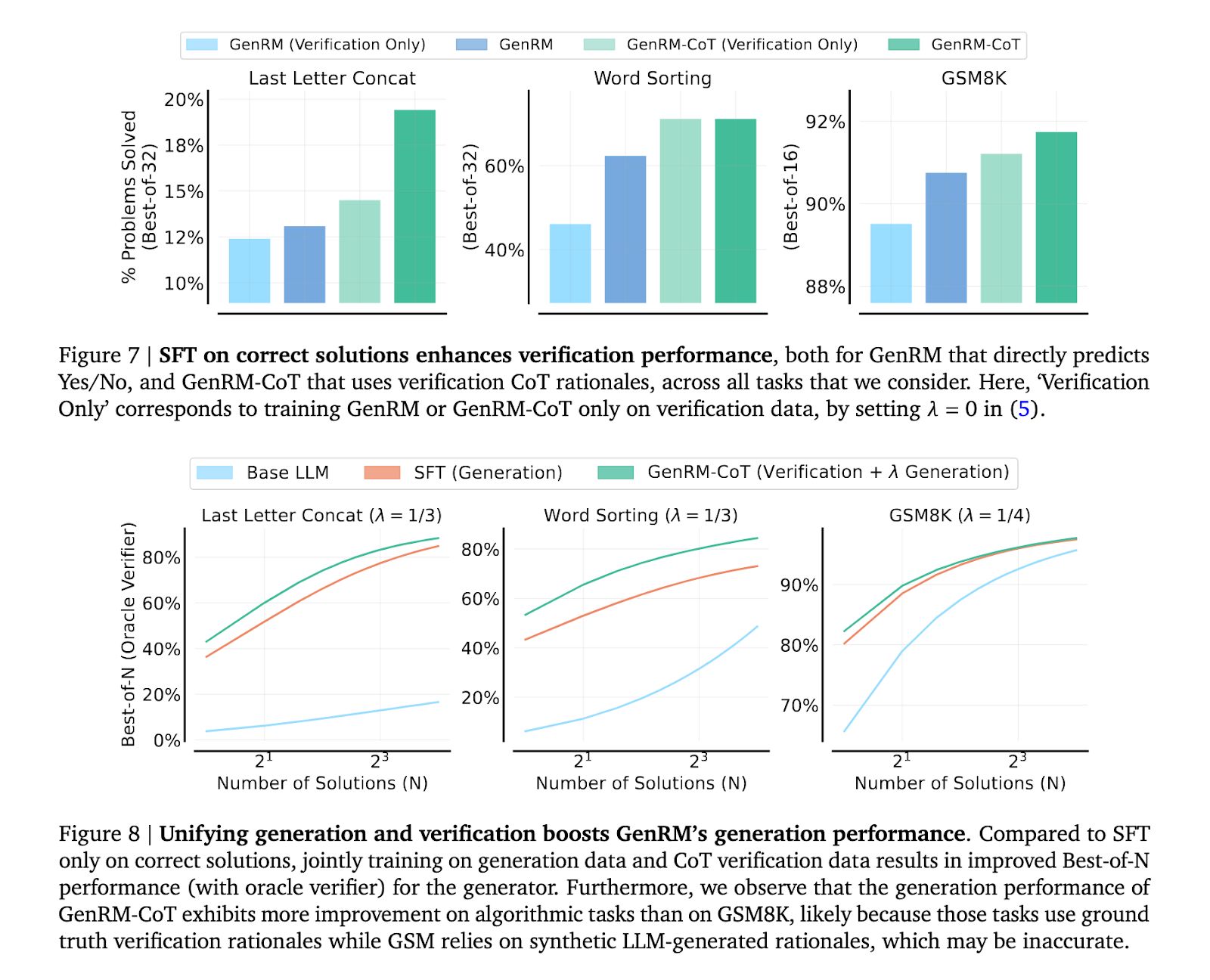
据 Google DeepMind 报道,GenRM 相对于分类奖励模型的改进标志着人工智能奖励系统的关键演进,尤其是在提升其容量方面,以防止新模型学会欺诈行为。这一进展突显了完善奖励模型的紧迫性,使人工智能的输出能够符合社会责任标准。
请提供参考地址。 (如果是要重写"附上参考地址"这句话,是否需要更具体的上下文信息呢?)


















