阿里云通义千问 Qwen2-VL 第二代视觉语言模型现已开源。
编辑日期:2024年09月03日

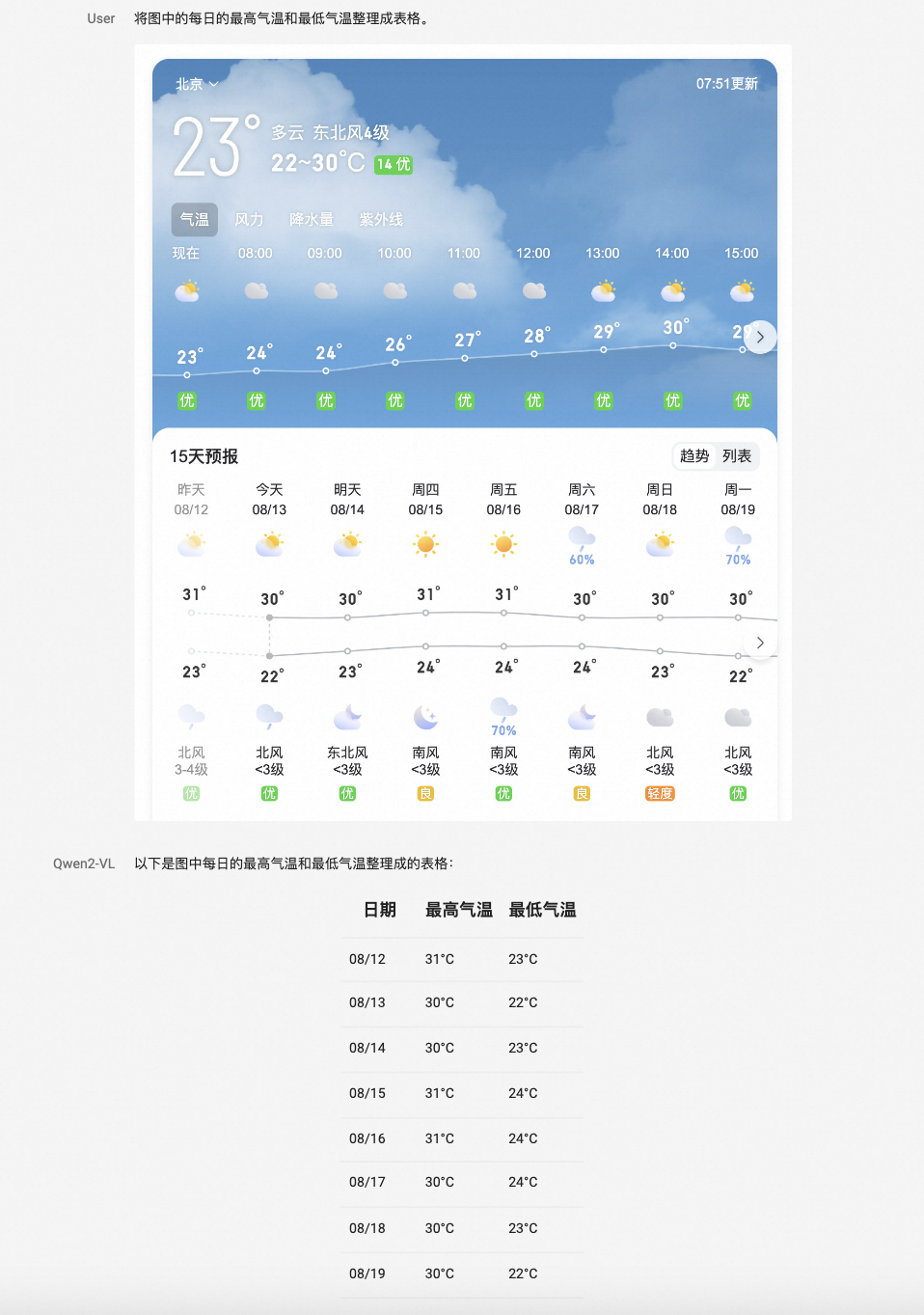
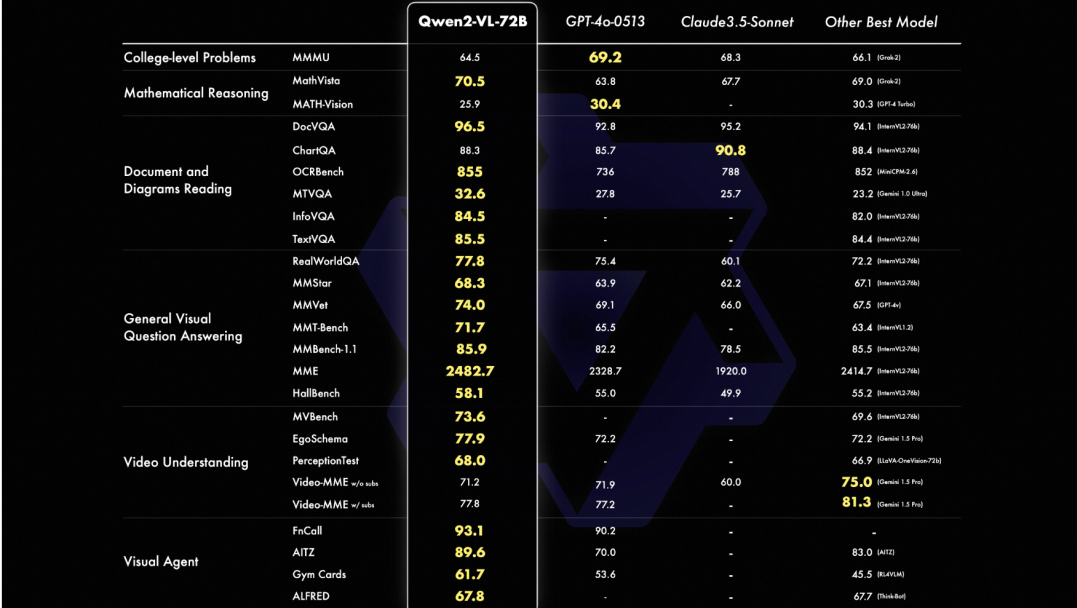
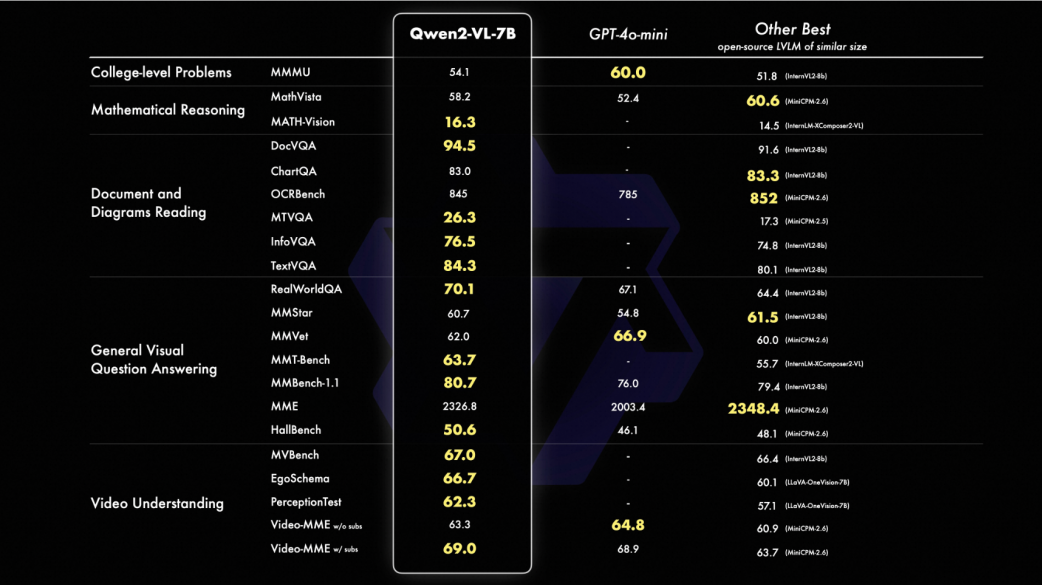
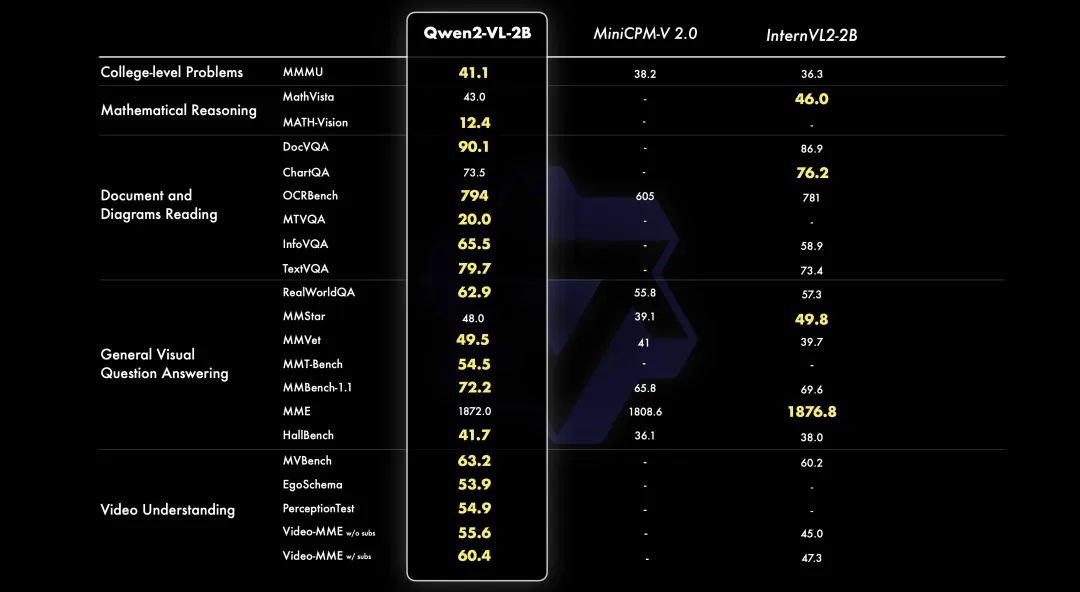
根据阿里云官方介绍,相较于上一代模型,Qwen2-VL的基础性能得到了全面升级和提升。
Qwen2-VL 继承了 ViT 与 Qwen2 的串联架构,所有三个尺寸的模型均采用了 600M 参数规模的 ViT,支持图像和视频的统一输入。
为了使模型更清晰地感知视觉信息并理解视频,团队对架构进行了一些升级:
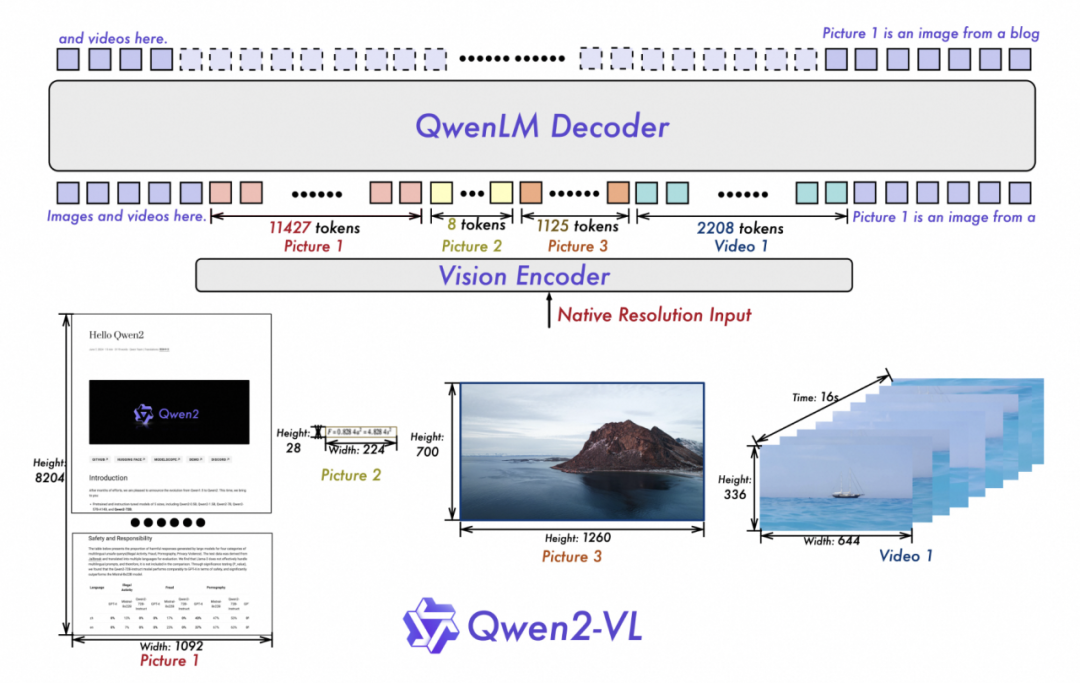
二是采用了多模态旋转位置嵌入(M-ROPE)方法。传统的旋转位置嵌入只能捕获一维序列的位置信息,而M-ROPE使大规模语言模型能够同时捕捉并整合一维文本序列、二维视觉图像及三维视频的位置信息,从而赋予了语言模型强大的多模态处理和推理能力,使模型能够更好地理解和建模复杂的多模态数据。

此次开源的 Qwen2-VL 系列模型中的旗舰模型 Qwen2-VL-72B 的 API 已在阿里云百炼平台上架,用户可以通过阿里云百炼平台直接调用该 API。
同时,通义千问团队根据 Apache 2.0 协议开源了 Qwen2-VL-2B 和 Qwen2-VL-7B,并将开源代码集成到了 Hugging Face Transformers、vLLM 以及其它第三方框架中。开发者可以通过 Hugging Face 和魔搭 ModelScope 下载并使用这些模型,也可以通过通义官网和通义 App 的主对话页面进行使用,具体地址如下: