小模型越级挑战14倍参数的大模型,谷歌开启测试时的新扩展法则。
编辑日期:2024年09月11日
在扩展模型测试时,计算资源的优化可能比单纯增加模型参数更为有效。
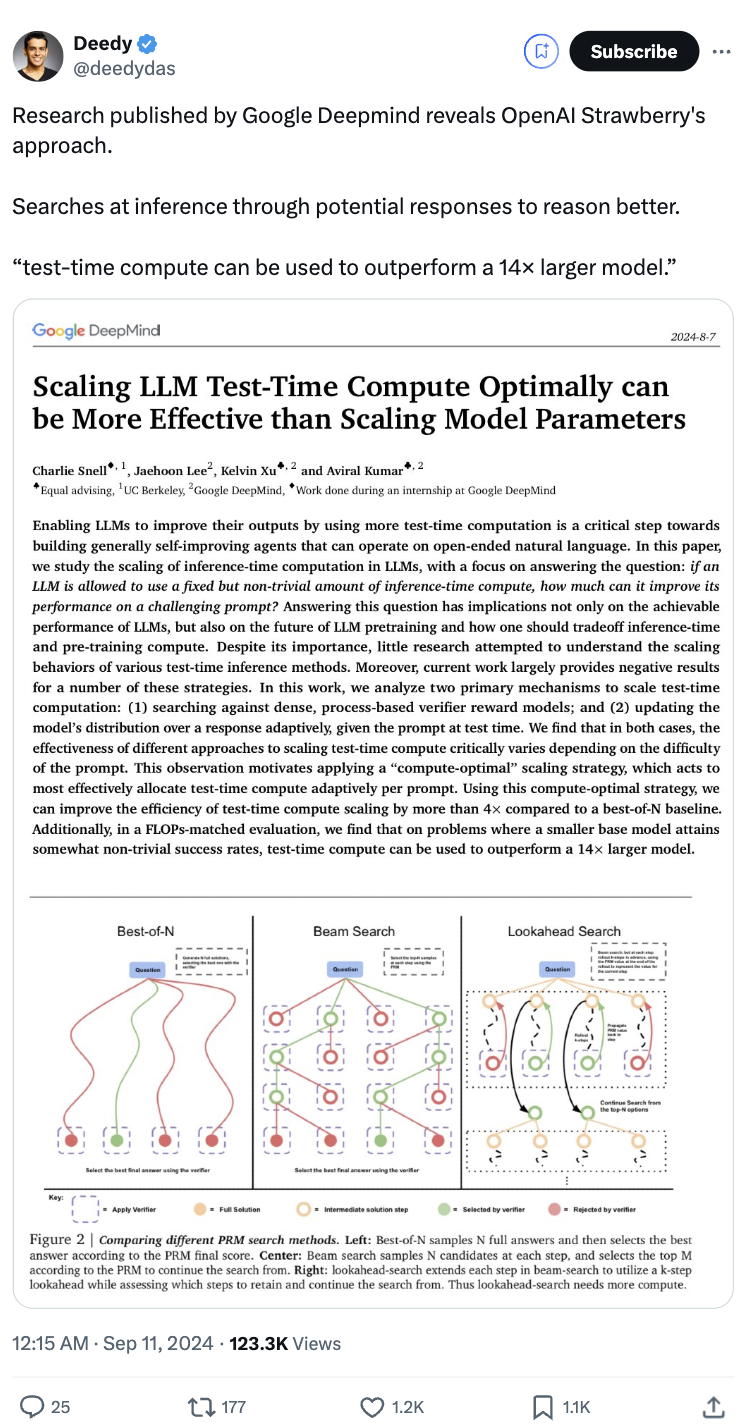
无需增加模型参数,在相同的计算资源下,小型模型的表现竟然超越了参数量是其14倍的大型模型!
这一发现来自谷歌DeepMind的最新研究,并引发了广泛讨论,甚至有人猜测这可能是OpenAI即将发布的新模型“草莓”所采用的方法。
研究团队探讨了在大型模型推理过程中进行计算优化的方法,即根据提示(prompt)的难度动态分配测试时(Test-Time)的计算资源。结果显示,这种方法在某些情况下比简单增加模型参数更具成本效益。
换句话说,在预训练阶段减少计算资源的使用,而在推理阶段增加计算资源,这种策略可能更加高效。
这项研究的核心问题在于:在固定的计算预算下解决提示问题时,不同的计算策略对不同问题的有效性存在显著差异。我们应该如何评估并选择最合适的测试时计算策略?这种策略与直接使用更大规模的预训练模型相比,效果如何?
DeepMind的研究团队主要探讨了两种扩展测试时计算的方法:
一种是针对基于过程的密集验证器奖励模型(PRM)进行搜索。PRM可以在模型生成答案的过程中每一步都提供评分,用于引导搜索算法,动态调整搜索策略。通过识别生成过程中的错误或低效路径,PRM能够帮助避免在这类路径上浪费计算资源。
另一种方法是在测试过程中根据提示(prompt)自适应地更新模型的响应分布。在这种方法中,模型不会一次性生成最终答案,而是逐步修改和完善之前生成的答案,按顺序进行迭代。
以下是并行采样与顺序修订的比较。并行采样独立生成多个答案,而顺序修订则是在每次生成新的答案时依赖于前一次生成的结果,并逐步修订。
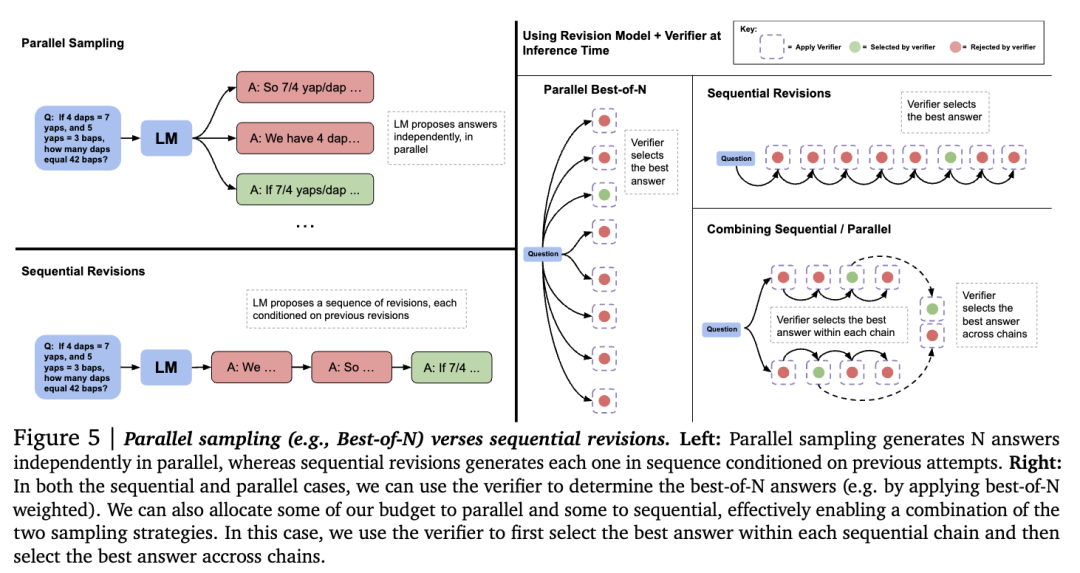
研究团队发现,这两种策略的有效性高度依赖于提示的难度。

基于这些发现,研究团队提出了一种“计算最优”的扩展策略,该策略可以根据提示的难度自适应地分配测试时的计算资源。他们将问题分为五个难度等级,并针对每个等级选择最佳策略。
如图所示(左侧),在修订场景中,传统的best-of-N方法(即生成多个答案后选择最优的一个)与计算最优扩展策略相比,差距逐渐扩大。这意味着在使用少4倍的测试计算资源的情况下,计算最优扩展策略仍能超越best-of-N方法。
同样,在PRM搜索环境中,计算最优扩展策略在初期相比best-of-N有显著提升,甚至在某些情况下,以少4倍的计算资源接近或超过best-of-N的表现。
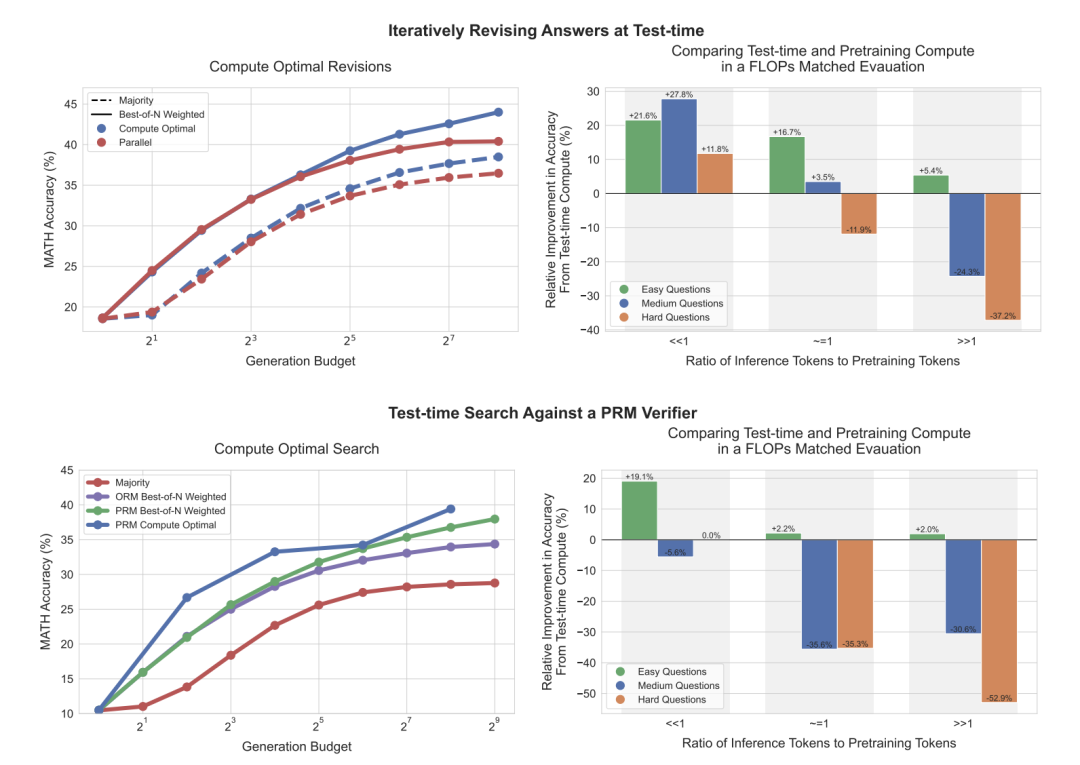
上图右侧展示了在测试阶段采用计算最优扩展策略的PaLM 2-S模型与未使用额外测试计算的预训练模型之间的表现对比,后者是一个参数量大14倍的预训练模型。
研究人员假设在这两种模型中都会预期有𝑋 tokens的预训练和𝑌 tokens的推理。可以看到,在修订场景中(右上),当𝑌 << 𝑋时,测试阶段的计算通常优于额外的预训练。
然而,随着推理和预训练的 token 比率增加,在处理简单问题时,测试阶段的计算仍然是优先选择。对于较复杂的问题,预训练在这种情况下表现更优。研究人员在 PRM 搜索场景中也观察到了类似的趋势。此外,研究还对比了测试时计算与增加预训练的效果,在计算量相同的情况下,对于简单和中等难度的问题,额外的测试时计算通常优于增加预训练。而对于难度较大的问题,增加预训练计算则更为有效。

总体而言,研究揭示了当前的测试时计算扩展方法可能无法完全取代预训练的扩展,但在某些情况下已经显示出优势。
该研究被网友分享后,引发了热烈讨论。
有位网友甚至认为这解释了 OpenAI “草莓”模型的推理方法。
为什么这样说呢?
昨晚深夜,外媒 The Information 报道称,OpenAI 即将在未来两周内发布的新模型“草莓”,其推理能力大幅提升,用户输入无需额外的提示词。
“草莓”并没有一味追求 Scaling Law(规模定律),与其他模型最大的不同在于它会在回答前进行“思考”。
因此,“草莓”的响应时间需要 10-20 秒。

这位网友猜测,“草莓”可能采用了类似于谷歌 DeepMind 这项研究的方法(doge 表情):
如果你不同意,请给出一个替代的推理方法解释!

解释就解释:
本文讨论了best-of-n采样方法与蒙特卡洛树搜索(MCTS)。草莓可能是一个结合了特定tokens(如回溯、规划等)的混合深度模型。该模型或许会通过人类数据标注员以及来自易于验证领域(如数学和编程)的强化学习进行训练。

论文链接:https://arxiv.org/pdf/2408.03314
参考链接: [1] https://x.com/deedydas/status/1833539735853449360 [2] https://x.com/rohanpaul_ai/status/1833648489898594815
— 完 —
关注我们,及时了解最新科技动态

我们还能将静态图转化为动态图

实现了多个数量级的训练速度提升。

归纳、翻译和问答三大任务均能胜任

小模型挑战拥有14倍参数的大模型,谷歌两次错失率先发布ChatGPT的机会
(注:提供的图片链接无法访问,因此未包含图片内容)