给我一张脸,随意更换视频背景,林黛玉都被清华理工男用坏了|免费开放
编辑日期:2024年09月11日
告别“崩坏”:让AI视频中的任意主体保持一致
现在,只需简单几步,人人都可以轻松实现这一目标。


只需一张图片,就能实现这一效果。
——以上每个马斯克的视频片段,都源自同一张照片。

要尝试这一功能,只需使用清华大学系AI视频公司生数科技旗下的Vidu最新推出的“主体参照(Subject Consistency)”功能。
该功能可确保视频中任意主体的形象保持一致,使视频生成更为稳定且可控。

生数科技CEO唐家渝表示:“目前生成AI视频内容时,要做到‘言出法随’仍较为困难。由于不确定性因素,视频内容在运镜和光效等方面的精细控制仍需不断调整。‘角色一致性’仅能保持人脸一致,而‘主体参照’则可确保主体的整体造型一致,从而提供更大的创作空间。”
这是继今年7月生数Vidu面向全球用户推出文字生成视频和图像生成视频功能(单视频最长生成8秒)后的又一次更新。
此次功能更新依然非常友好:
- 面向用户免费开放,注册即可体验。

让我们来看一下Vidu是如何定义这一新功能的:
主体参照:允许用户上传任意主体的一张图片,Vidu将锁定该主体形象,并通过描述词自由切换场景,输出主体一致的视频。
重点:适用于任意主体
无论对象是人还是动物,不论是真人、动漫角色还是虚构主体,甚至是家具或商品,都可以通过这一功能在视频生成过程中实现一致性和可控性。
目前,在所有视频大模型中,只有Vidu率先支持这种玩法。
现在,让我们来看一下实际效果。
首先,我们来看看以人物为主体的情况。
上传一张87版《红楼梦》中林黛玉的定妆照:

以画面中的林黛玉为主体,利用主体参照功能,生成两条视频。
突然间,林黛玉上台演讲了:

转眼间,她又坐在星巴克喝咖啡了:

当然,除了真人,虚拟角色或动漫人物也可以作为生成视频的主体。
例如,输入一张漫画女孩的图片:

生成的视频效果如下:

这里还有一些官方给出的小贴士:
谁能不喜欢可爱的狗狗呢!

将这张照片交给Vidu,就能实现狗狗在草地上行走,并一步步向你靠近的效果。
镜头后拉和主体运动幅度表现都很不错。
当我们需要将商品作为视频中的主要参照对象时,生成的视频应当使商品的外观和细节在不同的背景场景中保持一致。
例如:

可以看到,沙发所在的背景可以随意变换。
同时,沙发上还可以有一个盖着毯子的小女孩,遮住沙发的一部分。

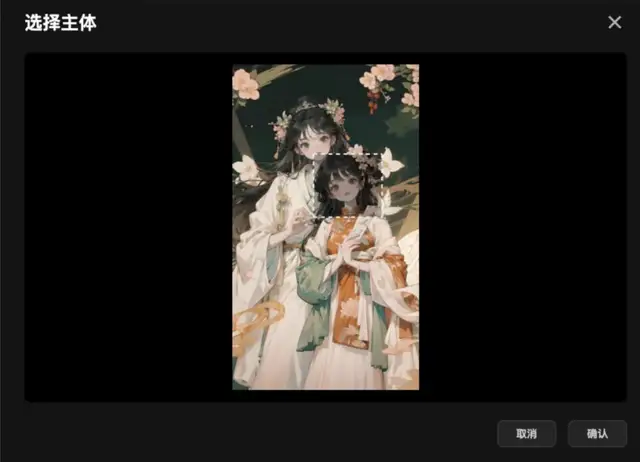
需要注意的是,当前版本只支持对单一主体进行控制。
如果上传的图片中有多个对象,需要选择其中一个单一主体来进行生成。
例如:
不论是制作短视频、动画作品还是广告片,“主体一致、场景一致、风格一致”都是共同的目标。
因此,为了让AI生成的视频内容具有更好的叙事效果,我们需要尽量做到这三个“一致”。
特别是在实际应用中,视频的内容通常会围绕某个特定对象展开。这是视频生成中最容易出现问题的部分,尤其是在涉及复杂的动作和互动时。
头痛啊。

目前业界常用的方法是先通过AI生成图像,再将这些图像转换成视频。
简单来说,就是利用Midjourney或Stable Diffusion等工具生成分镜头画面,并确保每个画面中的主体保持一致,然后再将这些图像转换为视频,并进行最终的拼接和剪辑。
一听就知道,这种方式无论是保持 AI 作图的一致性,还是后期的拼接和剪辑,都会带来很大的工作量。而生数 Vidu 的“主体参照”方法则有所不同,它不再分两步走,而是通过上传主体图像并输入场景描述词的方式,直接生成视频素材。
最后,我们来澄清并区分以下三个概念:
-
图生视频:这是当前 AI 视频生成的基本操作。它将输入的图片作为视频的第一帧,并在此基础上连续生成后续帧。然而,这种方法的局限在于无法直接生成目标场景,从而限制了视频内容的多样性和场景的自由度。
-
角色一致性:主要作用于人物形象。它可以确保人物的面部特征在动态视频中保持一致,但通常这种“一致性”仅限于面部,而不涵盖整个形象。
-
主体参照:适用于任何主体。当应用于人物主体时,不仅可以选择保持面部一致性,还可以选择保持人物整体形象的高度一致性。
最后附上生数科技的视频试玩链接。有兴趣的朋友可以趁现在排队的人不多,赶紧去体验一波!毕竟,免费的东西总是更受欢迎,对吧(doge)。
体验地址:www.vidu.studio

应当助推“人工智能+”,而不是“+人工智能”

团队成果三次与 OpenAI 大撞车
累计获得10亿豪华融资破纪录

“集结开源社区力量”
 新功能已全面上线
新功能已全面上线

复制Sora并非唯一的选择