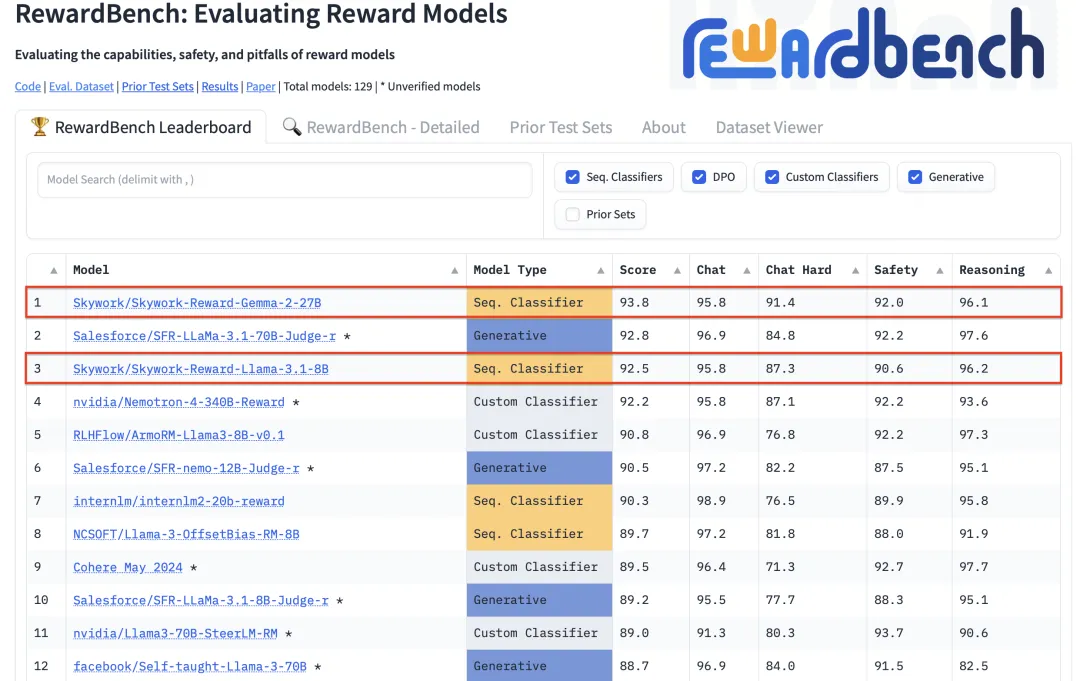
昆仑万维发布了奖励模型Skywork-Reward,并在RewardBench排行榜上位居第一。
编辑日期:2024年09月13日
奖励模型(Reward Model)是强化学习(Reinforcement Learning)中的核心概念和关键组成部分,用于评估智能体在不同状态下的表现,并通过提供奖励信号来引导智能体的学习过程,从而使智能体能够在特定环境中学会做出最优决策。
奖励模型在大型语言模型(Large Language Model,LLM)的训练中尤其重要,能够帮助模型更好地理解和生成符合人类偏好的内容。
与现有的奖励模型不同,Skywork-Reward 的偏序数据完全来源于网络上的公开数据,并采用特定的筛选策略,以获取针对特定能力和知识领域的高质量偏好数据集。
Skywork-Reward 偏序训练数据集包含了大约 80,000 个样本。通过在这些样本上对 Gemma-2-27B-it 和 Llama-3.1-8B-Instruct 基础模型进行微调,最终得到了 Skywork-Reward 奖励模型。
以下是相关链接: