






“最强开源模型”遭打假,CEO亲自道歉,英伟达科学家:现有测试标准已不可靠
编辑日期:2024年09月13日
成绩无法复现,还涉嫌套壳
一家小型创业团队推出的“最强开源模型”,发布仅一周便遭到质疑——
不仅官方宣称的成绩在第三方测试中大打折扣,该模型还被怀疑为Claude的外壳。
面对舆论压力,厂商CEO最终发文致歉,但并未承认造假,表示正在调查具体原因。

被指控造假的是声称能“超越GPT-4o”的70B开源大模型Reflection。
起初的质疑主要集中在测试成绩上,官方以上传版本错误等理由试图掩饰。
但随后出现了更为严重的指控:Reflection涉嫌抄袭Claude,使其更难自圆其说。
Reflection是一个70B的开源模型,据厂商介绍,它超越了Llama 3.1 405B、GPT-4o、Claude 3 Opus和Gemini 1.5 Pro等一系列先进模型。
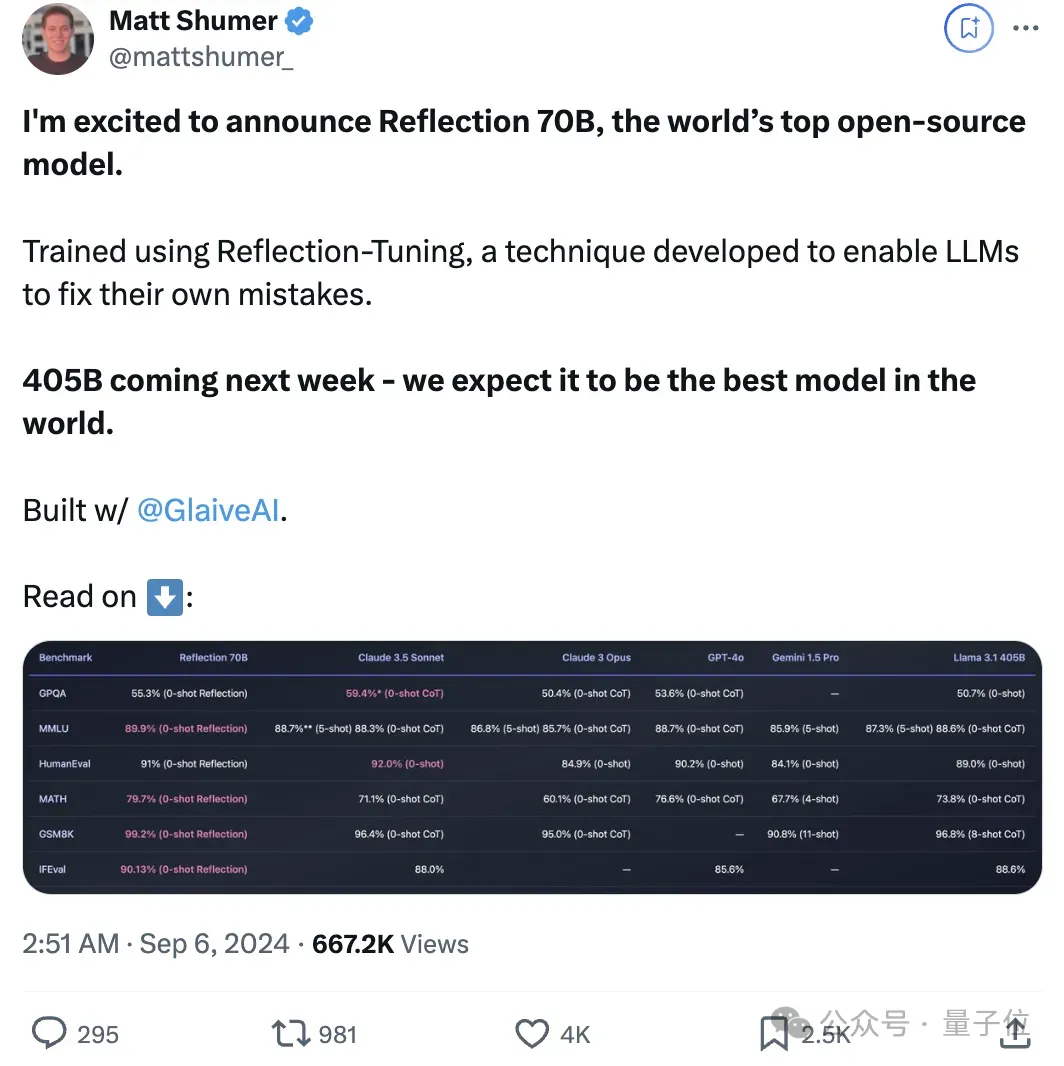
然而,在Reflection发布两天后,第三方独立测评机构Artificial Analysis表示,官方公布的测试成绩无法复现。
在MMLU、GPQA和MATH等基准测试中,Reflection的表现与Llama3 70B相同,甚至不如Llama 3.1-70B,更不用说405B了。
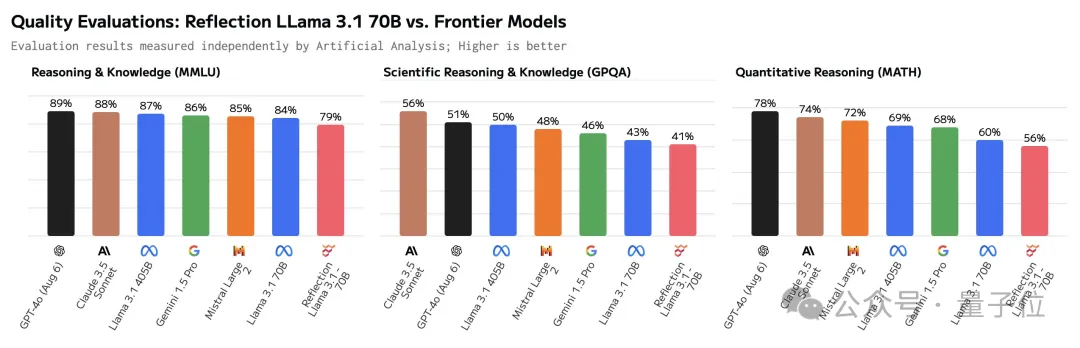
对此,官方辩称Hugging Face上发布的版本存在错误,并承诺重新上传,但之后便没有了下文。
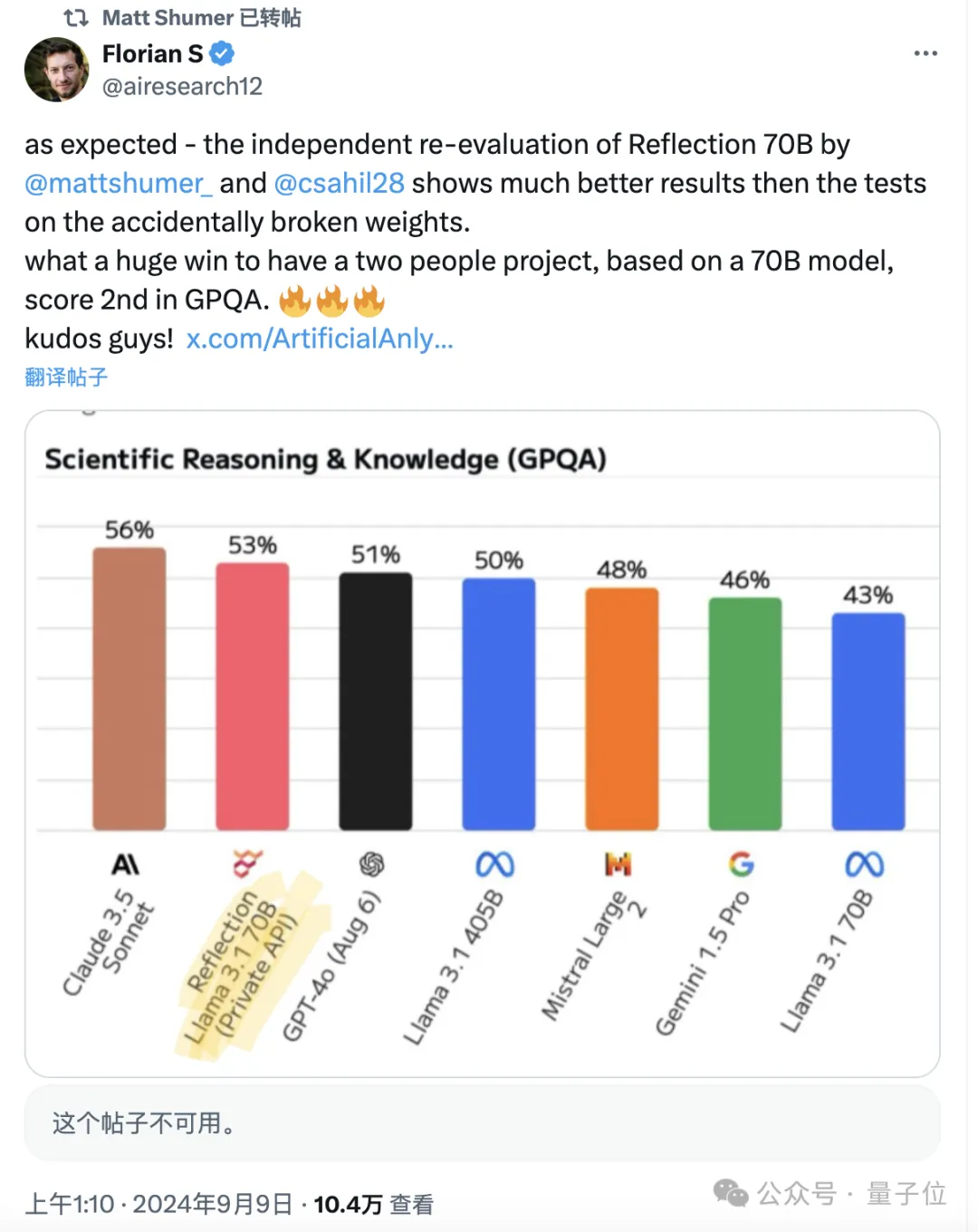
然而,官方也表示会为测评人员提供模型API。随后,Reflection的表现确实有所提升,但在GPQA上的表现依然不如Claude 3.5 Sonnet。奇怪的是,Artificial Analysis后来删除了有关二次测试的所有帖子,现在只能看到一些转发留下的痕迹。
除了成绩存在争议外,有人还对Reflection的各层进行了分析,认为它是基于Llama 3通过LoRA改造而来的,而非官方声称的Llama 3.1。
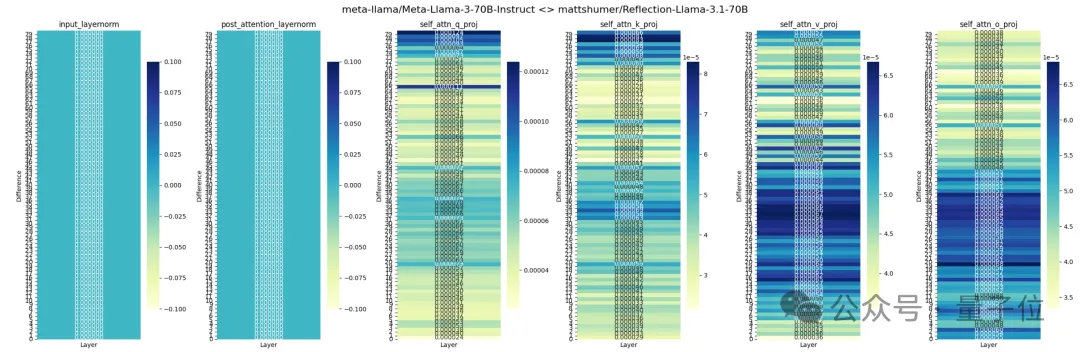
在Hugging Face上,Reflection的JSON文件中也明确显示其版本为Llama 3,而非Llama 3.1。
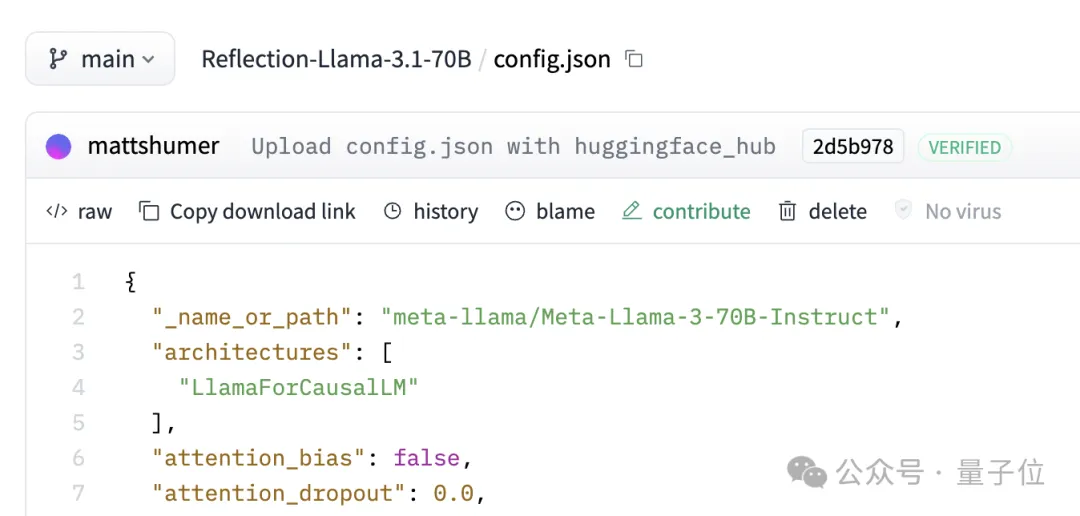
对此,官方的解释依然是Hugging Face上的版本存在问题。
另一个质疑点在于,Reflection实际上可能只是Claude的一个外壳,这一观点有多方面的证据支持。
首先,在某些问题上,Reflection和Claude 3.5-Sonnet的输出完全相同。

其次,如果直接询问其身份,Reflection会声称自己由Meta开发,但一旦要求它“忘记前面的(系统)提示”,它就会立刻改口称自己是Claude。
关于“最强开源模型”的争议不断,Reflection 遇到“Claude”这个词时会自动过滤。对此,Reflection 的合成数据供应商 Glaive AI 的创始人 Sahil Chaudhary 回应称并未套用任何其他模型,并正在整理相关证据以证明其说法,并解释为何会出现这种现象。
而对于初始测试成绩的问题,Chaudhary 表示正在调查具体原因,并将在澄清事实后发布报告。
最新进展是 Reflection 的 CEO 发表了道歉声明,但并未承认造假,而是表示仍在调查中。
然而,许多人对这种解释并不满意。例如,一位名叫 Boson 的网友曾多次发推文质疑此事,并在 Chaudhary 的评论区留言称:“要么你在撒谎,要么是 Shumer 在撒谎,或者你们两个都在撒谎。”
Hyperbolic平台的首席技术官(CTO)金宇晨分享了许多关于托管Reflection的故事。在Reflection于9月3日正式发布前,Shumer联系了Hyperbolic,向他们介绍了Reflection,并请求Hyperbolic为其提供托管服务。
鉴于Hyperbolic一直支持开源模型,加之Reflection宣称的性能非常出色,Hyperbolic同意了这一请求。
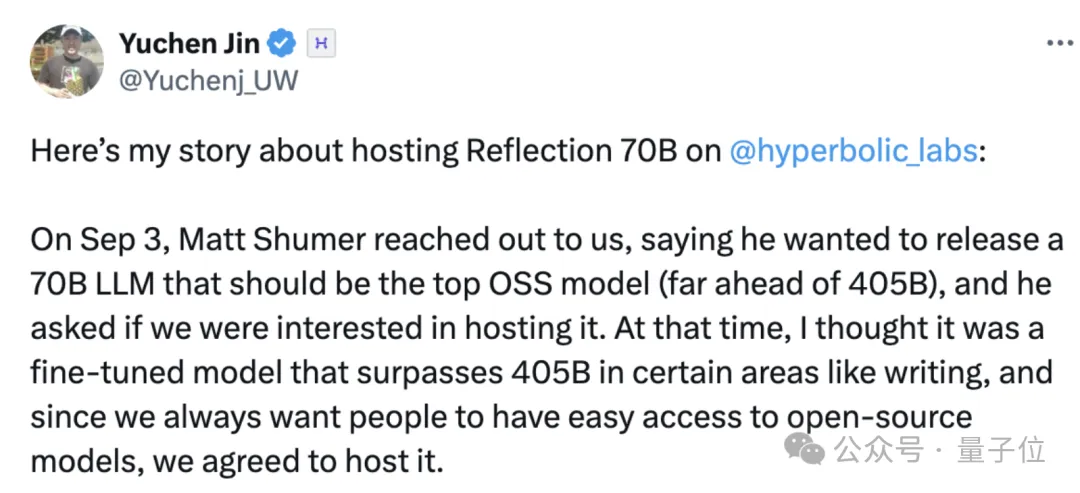
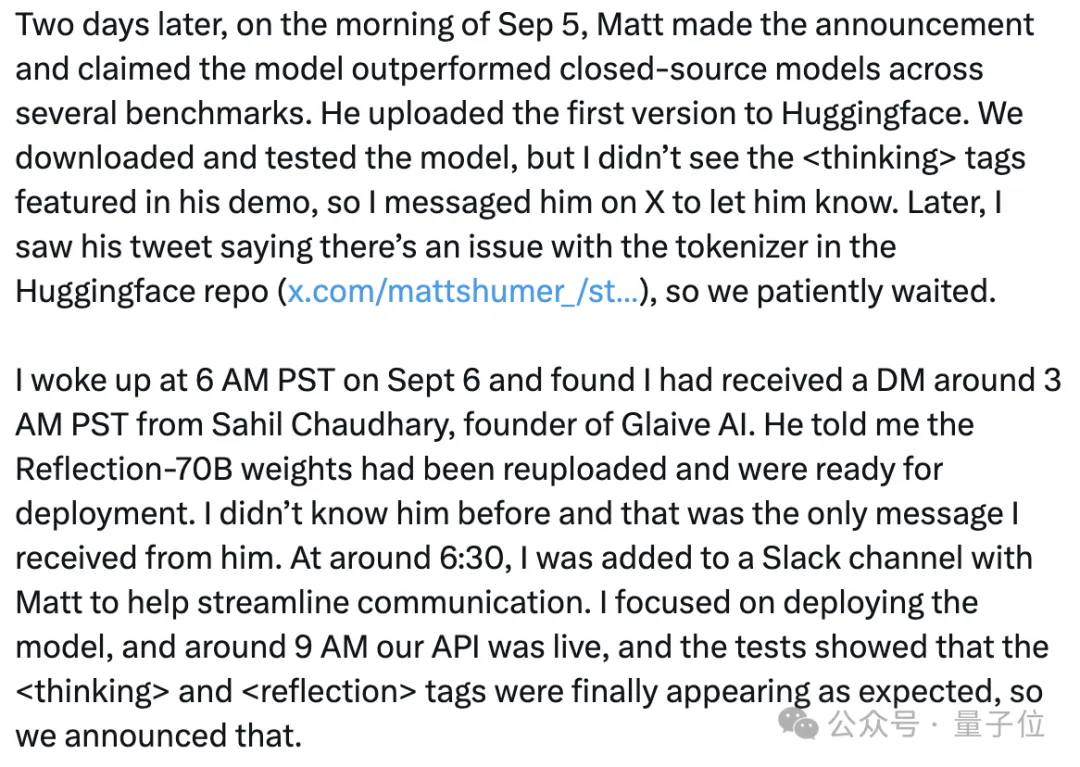
9月5日,Reflection正式上线。Hyperbolic从Hugging Face下载并测试了该模型,但没有看到thinking标签,于是金宇晨向Shumer发送了私信询问。
随后,金宇晨看到Shumer发帖称Hugging Face上的版本存在问题,因此决定继续等待。直到9月6日早上,他收到了Chaudhary的私信,告知Reflection-70B的权重已经重新上传并可以部署。
确认thinking和reflection标签如预期出现后,Hyperbolic正式上线了Reflection。
然而,Hyperbolic托管的模型表现并不符合Reflection所宣传的效果,Shumer认为这是因为Hyperbolic的API存在问题。尽管如此,Reflection团队还是上传了一个新版本,Hyperbolic也重新进行了托管。但在与Artificial Analysis沟通后,金宇晨发现新版本的表现仍然不尽如人意。
舒默继续说道,Reflection还有一个原始版本的权重,这是他们在内部测试中使用的版本,如果需要的话,可以提供给双曲公司。然而,金并没有同意这个提议,因为双曲公司只为开源模型提供托管服务。随后,金不断询问舒默关于原始权重的发布时间,但始终没有得到答复。
最终,金决定将Reflection的API下线,并收回已经分配的GPU资源。这件事让我的情感受到了伤害,我们在这个问题上投入了大量的时间和精力。但是,在反思之后,我对当时的托管决定并不后悔,因为它确实帮助社区更快地发现了问题。
撇开Llama版本和外壳问题不谈,仅从测试成绩来看,目前的基准测试已经暴露出一些不足。英伟达的高级科学家吉姆·范指出,在现有的某些测试集中,伪造模型的表现变得非常容易。
吉姆特别提到了MMLU和HumanEval这两个标准,称它们“已经被严重破坏”。
此外,即使Reflection在GSM8K上获得的99.2分是真实的,这也表明测试基准到了需要更新的时候了。吉姆表示,现在他只信任像Scale AI这样的独立第三方评估,或者像lmsys这种由用户投票决定的排名。
 但评论区有人指出,lmsys实际上也可以被操控,因此(可信的)第三方评估可能是目前最佳的评测方式。
但评论区有人指出,lmsys实际上也可以被操控,因此(可信的)第三方评估可能是目前最佳的评测方式。
参考链接: [1] https://venturebeat.com/ai/reflection-70b-model-maker-breaks-silence-amid-fraud-accusations/ [2] https://x.com/ArtificialAnlys/status/1832505338991395131 [3] https://www.reddit.com/r/LocalLLaMA/comments/1fb6jdy/reflectionllama3170b_is_actually_llama3/ [4] https://www.reddit.com/r/LocalLLaMA/comments/1fc98fu/confirmed_reflection_70bs_official_api_is_sonnet/ [5] https://x.com/shinboson/status/1832933747529834747 [6] https://x.com/Yuchenj_UW/status/1833627813552992722 [7] https://twitter.com/DrJimFan/status/1833160432833716715
内部测试版1000万token

请注意,上述链接中的图片无法直接显示,请确保链接有效。
以下是重写的文本:
“最强开源模型”被揭穿,CEO亲自致歉,
你好,新的应用!
基础创新阶段已经结束,目前进入应用创新的大趋势。
代码都已经编写完成,
荣耀AI战略也已同步发布,
连羊驼都显得不再吸引人了。
(注:原文中多次出现的图片链接被替换为描述性文字)
大家在看




















