O1核心作者分享:激发AI自我学习的能力,比试图教会AI每一项任务更为重要。
编辑日期:2024年09月20日
o1背后的新范式思考
“o1发布后,一个新的范式产生了。”
这一范式的背后关键人物之一是OpenAI的研究科学家、o1的核心贡献者Hyung Won Chung。他最近在麻省理工学院(MIT)的一次演讲中分享了他的观点。
演讲的主题是“Don’t teach. Incentivize(不要教,要激励)”,其核心观点是:
激励AI自我学习比试图教会AI每一项具体任务更重要。

思维链作者Jason Wei也迅速前来支持:
“Hyung Won识别新范式并完全放弃任何沉没成本的能力给我留下了深刻的印象。2022年底,他意识到强化学习的力量,并从那时起一直宣扬它。”

在演讲中,Hyung Won还分享了以下内容:
首先简要介绍一下Hyung Won Chung。从公布的o1背后人员名单来看,他是推理研究的基础贡献者。

资料显示,他是麻省理工学院(MIT)的博士,研究方向为可再生能源和能源系统。去年2月,他加入OpenAI担任研究科学家。
加入OpenAI之前,他在Google Brain负责大规模语言模型的预训练、指令微调、推理、多语言以及训练基础设施等方面的工作。

在谷歌工作期间,他曾以第一作者的身份发表了一篇关于模型微调的论文。(思维链作者Jason Wei也是该论文的第一作者)

回到正题。在麻省理工学院的演讲中,他首先提到:
实现AGI(通用人工智能)唯一可行的方法是激励模型,使其能够发展出通用技能。
在他看来,AI领域正在经历一场范式转变,即从传统的直接教授技能转变为激励模型自我学习和发展通用技能。
原因也很直观:AGI需要掌握的技能太多,无法逐一学习。(主要依靠不变应万变的方法)
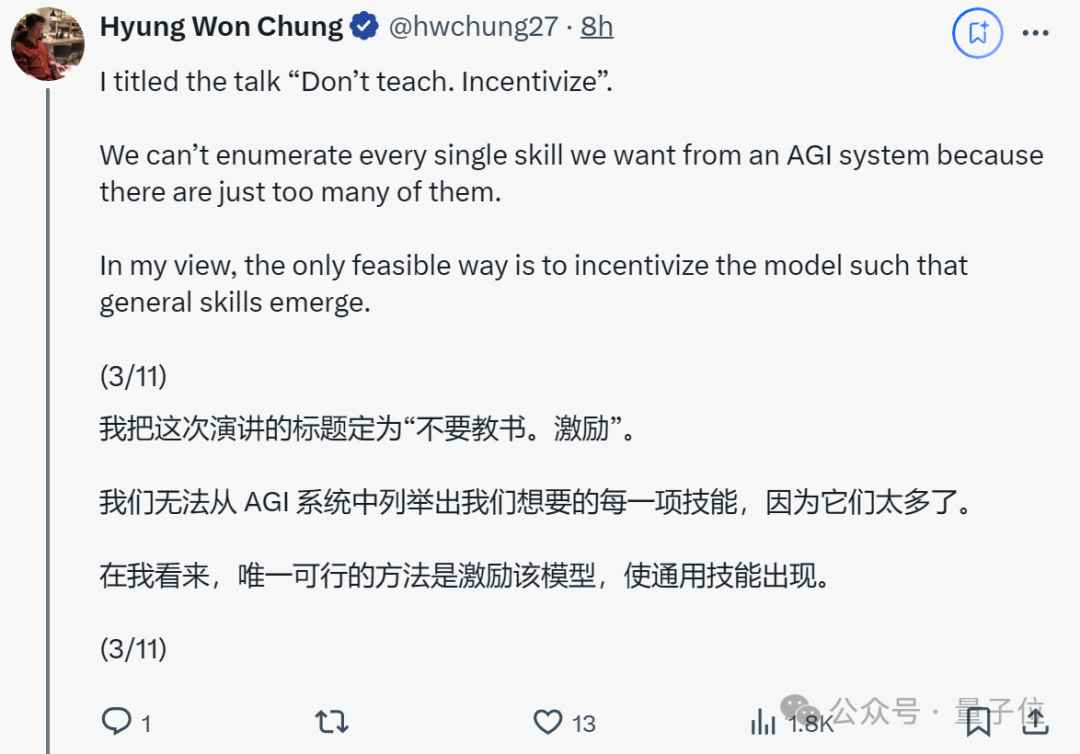
具体如何激励呢?
他以下一个token预测为例,解释了这种弱激励结构如何通过大规模多任务学习,鼓励模型学习解决数万亿个任务所需的通用技能,而不是单独解决每个任务。
他观察到:
如果试图解决数十个任务,那么单独识别每个任务可能是最简单的;但如果要解决数万亿个任务,通过学习通用技能(如语言处理和推理)可能会更容易解决它们。

对此,他打了一个比方:“授人以鱼不如授人以渔”,用一种基于激励的方法来解决问题。
“教AI尝尝鱼的味道,让它感到饥饿。”(教AI尝尝鱼的味道,让它饿一下)
然后AI会自己去钓鱼,在这个过程中,AI将学会其他技能,例如耐心、学习阅读天气、了解鱼类等。
其中一些技能是通用的,可以应用于其他任务。
面对这一“循循善诱”的过程,或许有人认为还不如直接教来得快。
但在Hyung Won看来:
对于人类来说确实如此,但对于机器来说,我们可以通过提供更多计算资源来缩短时间。
正如图所示,O1核心作者分享了关于激发AI自我学习能力的观点:在有限的时间里,人类或许还需在成为专家与通才之间做出选择,但对于机器而言,强大的算力则能创造奇迹。
他以《龙珠》中的设定为例,说明在一个特殊的训练场所,角色可以在外界仅过一天的时间里完成一年的修炼。对于机器来说,这种时间感差距更为显著。因此,具备强大计算能力的通用型机器往往比专精型机器更能胜任特定领域的工作。这背后的原因众所周知——大型通用模型能够通过大规模训练和学习,迅速适应并掌握新任务和领域,无需重新开始训练。
他还补充说,数据显示,计算能力大约每五年就会提升十倍。
总结起来,Hyung Won认为关键在于以下几点:
此外,他认为目前存在一种误解,即人们正试图让AI学会像人类一样思考。然而,问题在于我们并不清楚在神经元层面上人类是如何思考的。因此,机器应当拥有更多的自主权去选择学习方式,而不应被局限于人类理解的数学语言和结构中。在他看来,如果一个系统或算法过度依赖于人为设定的规则和结构,那么它将难以应对新的、未预见的情况或数据,从而在处理更大规模或更复杂的问题时,其扩展能力也将受到限制。
回顾AI过去七十年的发展历程,他总结道:
AI的进步与减少人为结构、增加数据量及计算能力密切相关。
与此同时,针对当前对“扩展定律”(scaling law)的质疑——即单纯扩大计算规模被认为缺乏科学性和趣味性——Hyung Won的观点如下:
在扩展系统或模型的过程中,我们需要找出那些阻碍扩展的假设或限制条件。
例如,在机器学习中,某个模型可能在小数据集上表现优异,但在数据量增大后,其性能可能会下降,或者训练时间会变得难以接受。
此时,我们可能需要改进算法、优化数据处理流程,或是调整模型结构,以适应更大规模的数据和更复杂的任务。
换句话说,一旦确定了瓶颈所在,就需要通过创新和改进来替代这些假设,从而使模型或系统能够在更大的规模上高效运行。
此外,O1的另一位核心作者Noam Brown也提出了一个观点:
虽然训练和推理都能提升模型性能,但推理的成本要低得多,大约便宜1000亿倍。

这意味着,在模型开发过程中,训练阶段的资源消耗极其庞大,而在实际使用模型进行推理时的成本则相对较低。
有人认为这表明了未来模型优化的巨大潜力。
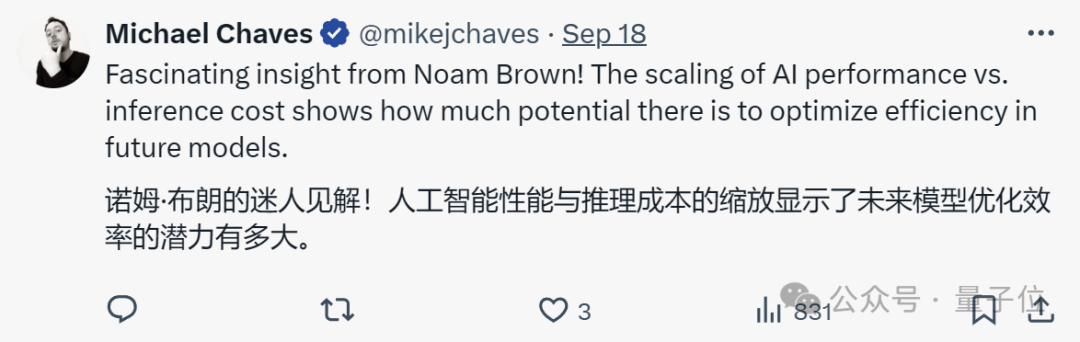
但也有人对此持怀疑态度,认为这种比较并不合理。
这是一种奇怪的比较。一方是边际成本,另一方则是固定成本。这就好比说实体店比店内商品贵500000倍。
对此,你有何看法?