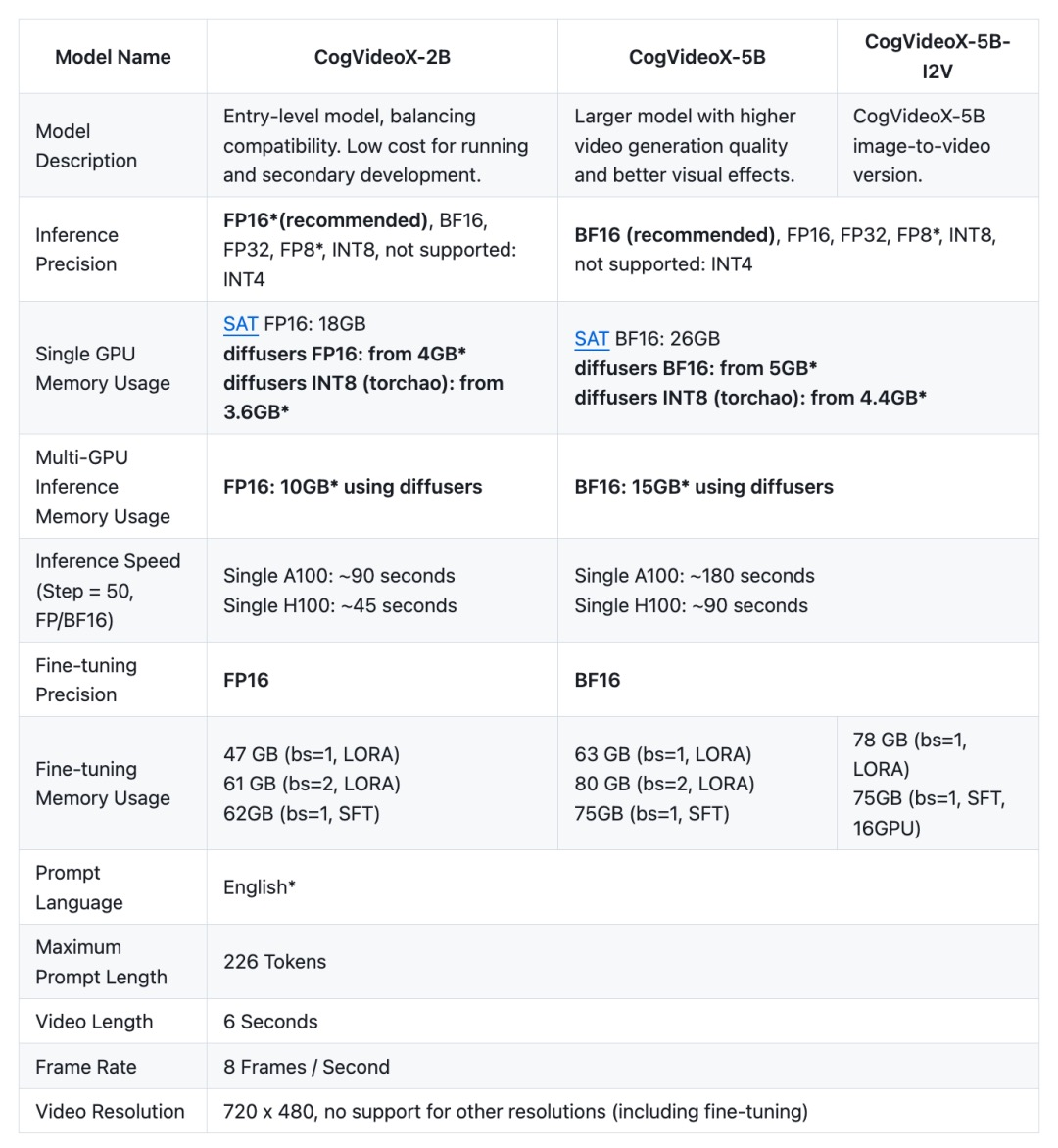
在线试玩!智谱开源图像生成视频模型,网友纷纷惊呼:太神奇了!
编辑日期:2024年09月20日
网友:Amazing!
刚才,智谱发布了其图生视频模型CogVideoX-5B-I2V的开源代码!(可在线体验)
一同发布的还有其标注模型cogvlm2-llama3-caption。
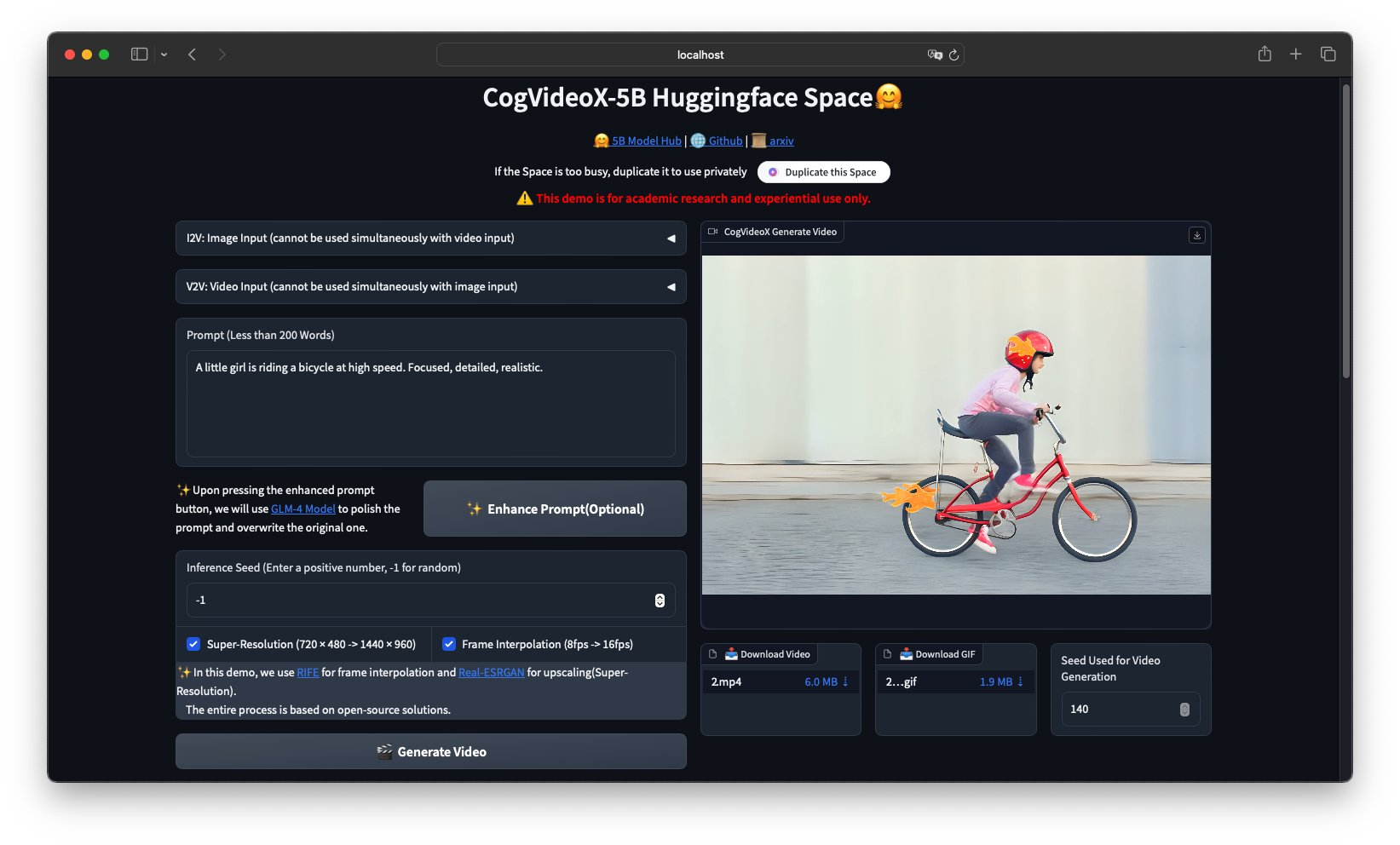
在实际应用中,CogVideoX-5B-I2V能够通过「一张图片」加上「提示词」生成视频。
而cogvlm2-llama3-caption则负责将视频内容转化为文本描述。
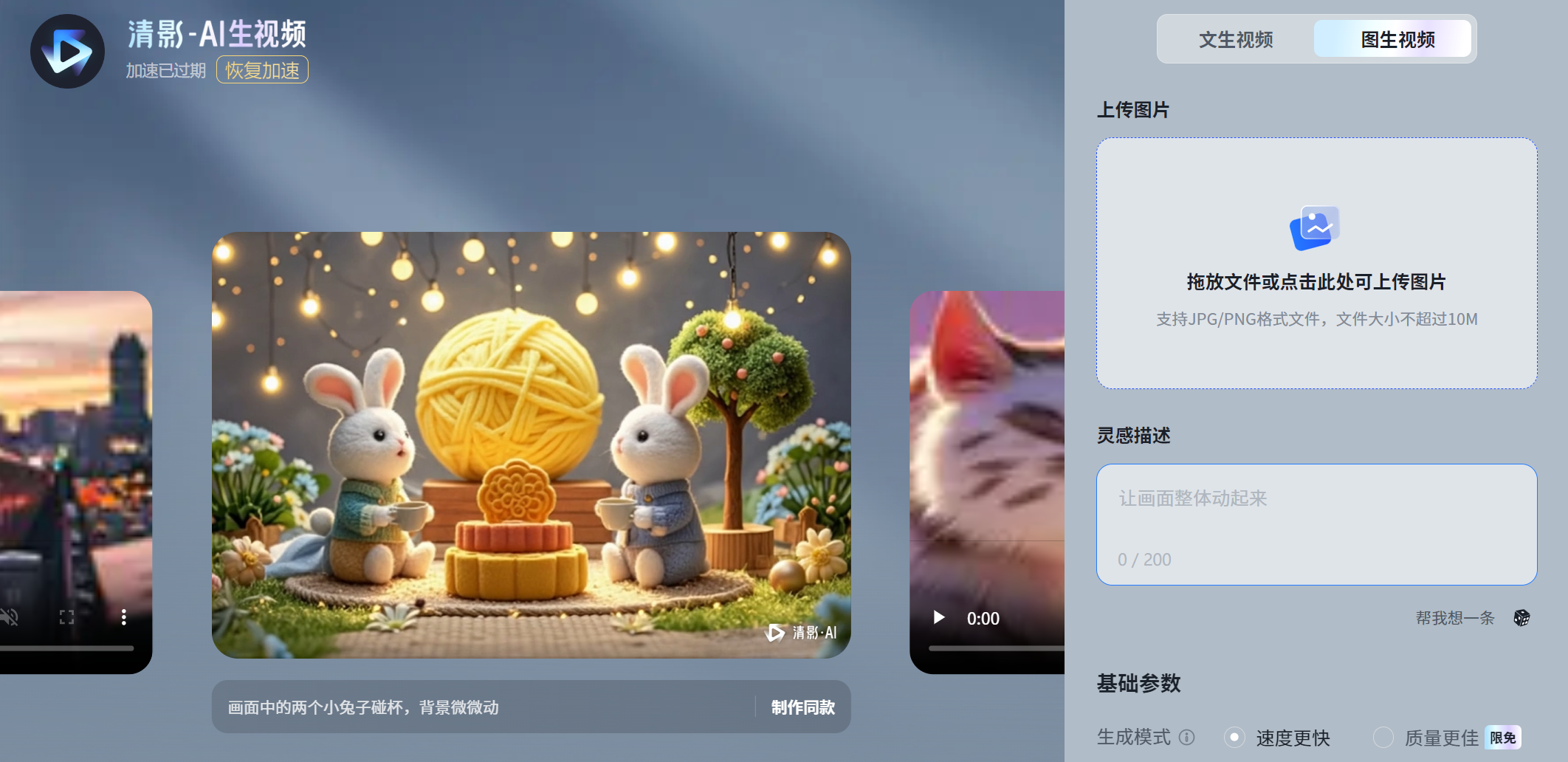
然而,使用过的网友们对其评价不一:
有人使用后直呼Amazing。

也有用户尝试了半天,最终还是选择回到CogVideoX的旧版本,并称赞道:我最看好这个版本!
那么,它实际的效果如何呢?我们来做个测试吧!
测试开始~ 输入提示词:咖啡店员握住双手笑着迎接客人,说话时身体自然活动(依然是常见的“手部”问题)
第二次测试,尝试了一个简短的提示词:吗喽跷着二郎腿打电话(效果不佳,主体仍然是静态的,没有动起来)
第三次的提示词为:“明月当空,几个人坐在河边谈心说话,举杯高歌。” 显示生成完成,但在最后展示阶段直接出现了NAN错误(呜呜呜)
整体效果有些难以评价,而且生成速度相对较慢。
让我们来看看团队发布的一些成功案例吧:
提示词:当万花筒般的蝴蝶在花朵间翩翩起舞时,花园变得生机勃勃,它们精致的翅膀在花瓣上投下阴影。
提示词:一位穿着西装的宇航员,靴子上沾满了火星的红色尘埃,在第四颗行星的粉红色天空下,他伸出手与一个外星人握手。
提示词:湖岸边长满了柳树,细长的枝条在微风中轻轻摇曳。平静的湖面倒映着清澈的蓝天,几只优雅的天鹅在水面上滑翔。
值得一提的是,目前CogVideoX-5B-I2V模型的代码已经全部开源,并支持在抱抱脸平台上部署。
相关研究论文也已公开,其中有三大技术亮点值得关注:

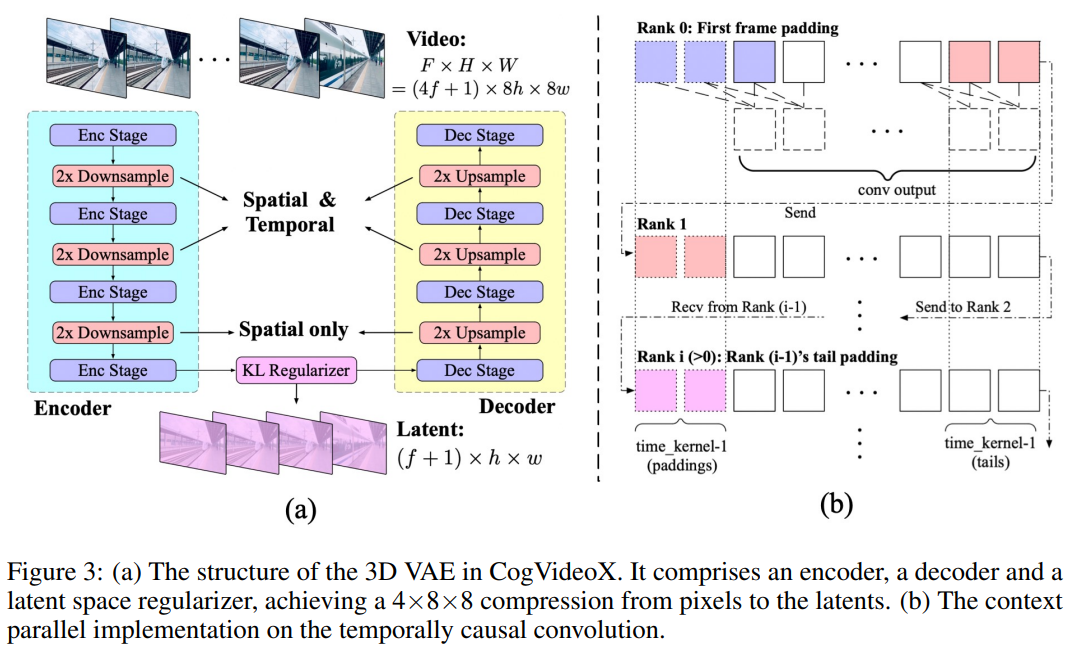
首先,团队自主研发了一种高效的三维变分自编码器结构(3D VAE),将原视频空间压缩至2%的大小,大幅降低了视频扩散生成模型的训练成本和难度。
该模型结构包括编码器、解码器和潜在空间正则化器,通过四个阶段的下采样和上采样实现压缩。时间因果卷积确保了信息的因果关系,减少了通信开销。团队还采用了上下文并行技术来适应大规模视频处理。
实验中,团队发现高分辨率编码易于泛化,但增加帧数则更具挑战性。
因此,团队分两个阶段训练模型:首先在较低帧率和小批量数据上进行训练,然后通过上下文并行技术在更高帧率上进行微调。训练损失函数结合了L2损失、LPIPS感知损失和3D判别器的GAN损失。
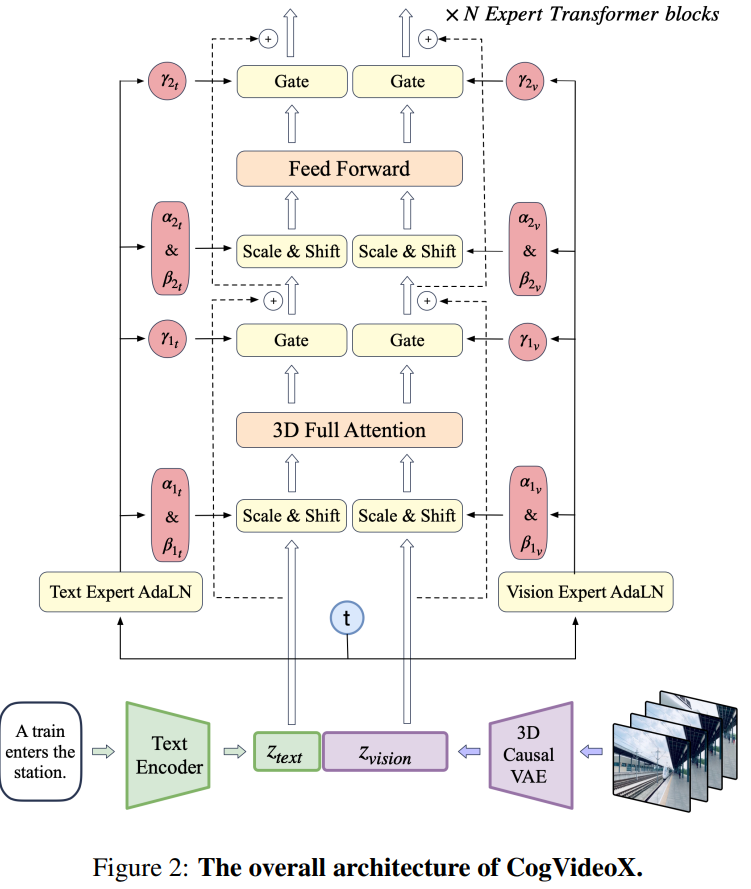
其次是专家Transformer模块。团队利用VAE的编码器将视频压缩到潜在空间,再将该潜在空间分割成块并展开成长序列嵌入z_vision。
同时,他们采用T5模型将文本输入编码为文本嵌入z_text,然后将z_text与z_vision沿着序列维度拼接起来。拼接后的嵌入被送入一系列专家Transformer块中进行处理。
最终,团队将嵌入逆向拼接以恢复原始潜在空间的形状,并使用VAE进行解码,从而重建视频。
接下来的重点在于数据处理。
团队开发了负面标签来识别和排除低质量视频,如过度编辑、运动不连贯、质量低劣、讲座风格、文本主导以及含有屏幕噪音的视频。
通过video-llama训练的过滤器,他们对20,000个视频数据点进行了标注和筛选。此外,他们计算了光流和美学分数,并动态调整阈值,以确保生成视频的质量。
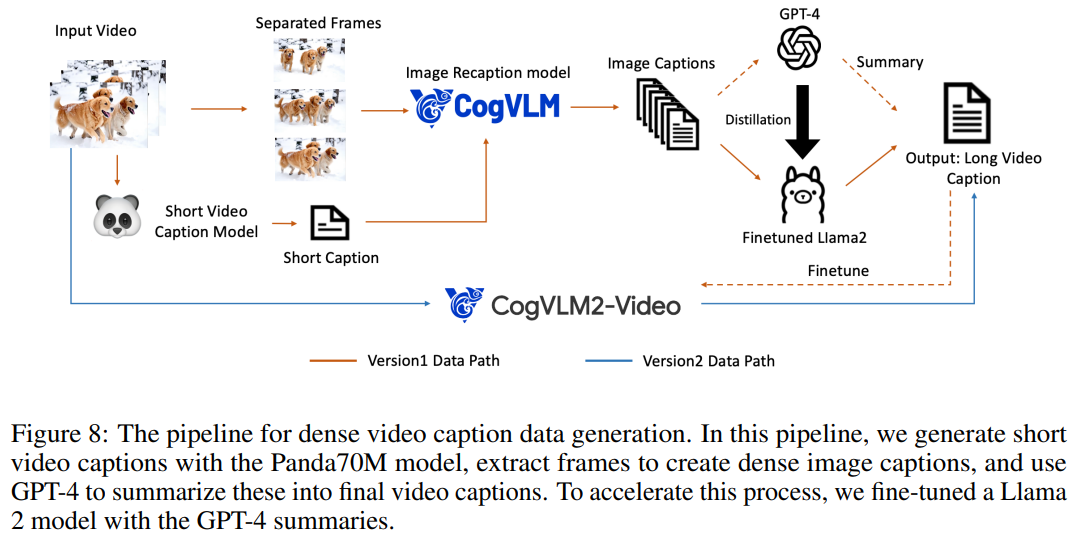
由于视频数据通常缺乏文本描述,因此需要将其转换为文本描述以便用于文本到视频模型的训练。然而,现有的视频字幕数据集中的字幕较为简短,无法全面描述视频内容。
为此,团队提出了一种从图像字幕生成视频字幕的方法,并微调了一个端到端的视频字幕模型以获得更详细的字幕。这种方法通过Panda70M模型生成简短字幕,使用CogView3模型生成密集的图像字幕,然后借助GPT-4模型总结生成最终的短视频字幕。
此外,他们还微调了一个基于CogVLM2-Video和Llama 3的CogVLM2-Caption模型,利用密集字幕数据进行训练,以加快视频字幕的生成过程。
值得一提的是,CogVideoX在过去的一个月里也没有闲着,持续更新了许多新功能!
2024年9月17日,发布了SAT权重的推理和微调代码以及安装依赖的命令,并使用GLM-4优化了提示词。 跳转链接:https://github.com/THUDM/CogVideo/commit/db309f3242d14153127ffaed06a3cf5a74c77062
2024年9月16日,用户可以通过本地开源模型、FLUX和CogVideoX实现自动化生成高质量视频。 跳转链接:https://github.com/THUDM/CogVideo/blob/CogVideoX_dev/tools/llm_flux_cogvideox/llm_flux_cogvideox.py
2024年9月15日,成功导出了CogVideoX的LoRA微调权重,并在diffusers库中通过了测试。 跳转链接:https://github.com/THUDM/CogVideo/blob/CogVideoX_dev/sat/README_zh.md
2024年8月29日,在CogVideoX-5B的推理代码中添加了pipe.enable_sequential_cpu_offload()和pipe.vae.enable_slicing()功能,将显存占用降低至5GB。
2024年8月27日,CogVideoX-2B模型的开源协议变更为Apache 2.0协议。
同一天,智谱AI开源了更大规模的CogVideoX-5B模型,显著提升了视频生成的质量与视觉效果。该模型优化了推理性能,使得用户能够在RTX 3060等桌面显卡上进行推理,降低了硬件要求。
2024年8月20日,VEnhancer工具现已支持对CogVideoX生成的视频进行增强,提升视频分辨率和质量。
2024年8月15日,CogVideoX所依赖的SwissArmyTransformer库更新至0.4.12版本,从此微调该库时无需再从源代码进行安装。此外,还引入了Tied VAE技术来优化生成效果。
此次CogVideoX-5B-I2V的开源,标志着CogVideoX系列模型现已支持文本生成视频、视频延长以及图像生成视频三种任务。