OpenAI 发布 MMMLU 数据集:更广泛、深入地评估 AI 模型,支持简体中文
编辑日期:2024年09月24日
随着语言模型的日益强大,评估其在不同语言、认知和文化背景下的能力已成为迫切需要。
OpenAI 决定推出 MMMLU 数据集,以应对这一挑战。该数据集通过提供强大的多语言和多任务支持,评估大型语言模型(LLMs)在各种任务中的性能。
MMMLU 数据集包含了一系列问题,涵盖了多种主题、学科领域和语言。其结构设计旨在评估模型在需要常识、推理、解决问题以及理解能力的不同研究领域任务中的表现。
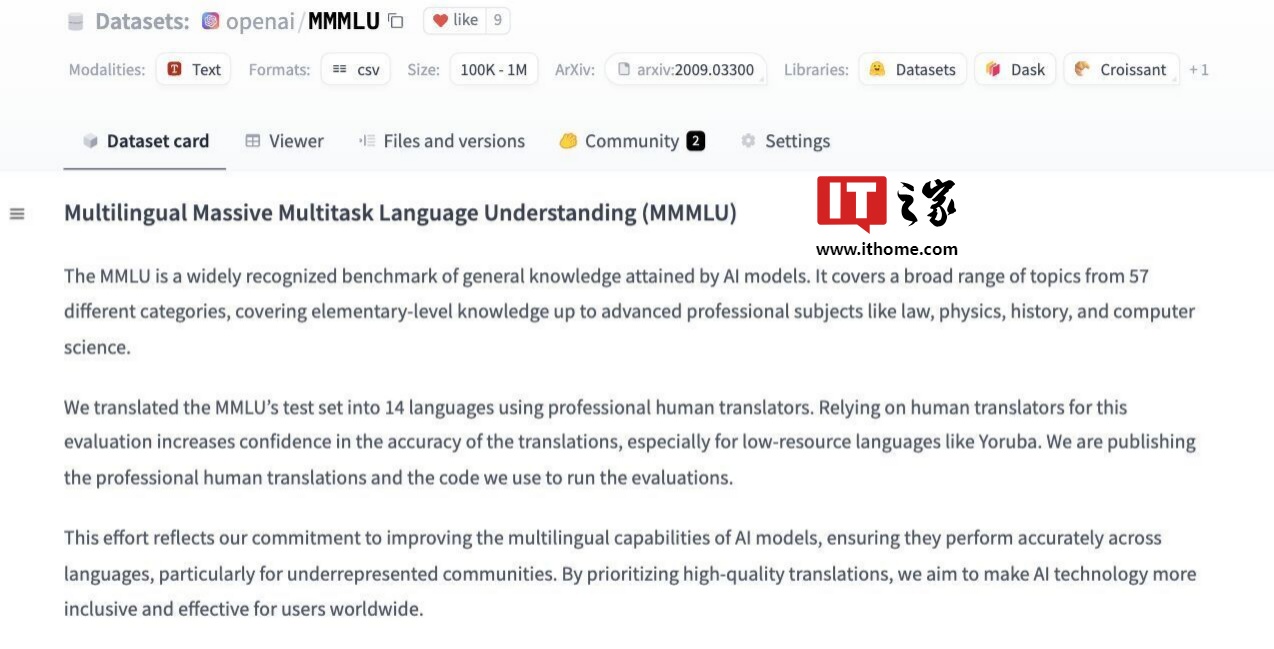
MMMLU的创建体现了OpenAI对测量模型实际能力的关注,特别是在那些在NLP研究中代表性不足的语言上。纳入多种语言不仅确保了模型在使用英语时的有效性,还使其能够胜任全球范围内其他语言的应用。
覆盖范围广泛
MMMLU 数据集是同类基准中最广泛的数据集之一,涵盖了从高中问题到高级专业和学术知识的多种任务。
研究人员和开发人员在使用 MMMLU 数据集时,可以调用不同难度的问题,以测试大型预测模型在人文、科学和技术主题上的表现。
更考验深层次的认知能力
这些问题都经过精心设计,旨在确保对模型的测试不仅限于表面理解,还能深入考察其在批判性推理、解释以及跨领域解决问题等更高级认知能力方面的表现。
多语言支持
(如果需要更多的上下文信息以更好地完成任务,请提供。否则,这已经是完整的重写。)
MMMLU 数据集的另一个显著特点是其多语言覆盖范围,包括简体中文。该数据集支持多种语言,能够进行跨语言的综合评估。

然而,用英语数据训练的模型在处理其他语言时往往需要额外的帮助以保持准确性和连贯性。MMMLU数据集提供了一个框架,用于测试在传统NLP研究中代表性不足的语言模型,从而填补了这一空白。
MMMLU的发布解决了人工智能领域中的几个相关挑战。它提供了一种更加多样化和文化包容性的方法来评估模型,确保这些模型在高资源语言和低资源语言中均能表现出色。
MMMLU 的多任务特性打破了现有基准的限制,能够评估同一个模型在不同任务中的表现,从琐事的事实回忆到复杂的推理和问题解决。这使得我们能够更详细地了解模型在各个领域的优点和不足。
请提供参考地址。 (如果是要重写"附上参考地址"这句话,是否需要更多的上下文信息以确保准确性和恰当性?)
大家在看