浩鲸科技发布鲸智BI大模型,实现从算法展示到实际应用的价值落地。
编辑日期:2024年09月24日
只需提出一个问题,即可获得数据分析的结果。
当前,国内行业大模型的竞争已不再局限于纯粹的算法网络比拼,而是转向了实际应用效果的较量。这不仅是一场技术展示,更是考验谁能在真实环境中大显身手,实现高效的落地应用,创造实际的社会价值。
9月20日,浩鲸科技在云栖大会上发布了鲸智大模型,其中鲸智BI大模型备受关注。据透露,基于鲸智BI大模型构建的鲸智ChatBI工具在中国信通院的可信AI评估中,跨越了四大智能领域的门槛,通过了20项能力测试,成为首个通过大模型商业智能系统评估的产品,并获得了业内最高的4+级评级,展示了其卓越的综合能力和智能技术水平。
浩鲸科技的数据智能首席专家吴名朝在发布会上表示,在将BI场景与大模型结合的过程中,仍面临诸多技术挑战,包括知识构建、问题准确性以及模型泛化等方面的问题。
随着数字化转型的不断推进,企业在数据量和业务复杂度上都面临着双重增长的挑战。为了支持高效决策并应对跨部门、跨流程、跨系统的复杂数据分析需求,数据架构需要进行升级。这要求分析人员具备高级的数据分析能力,提供集成的数据分析、商业智能及机器学习解决方案,确保各种数据需求能够得到统一且流畅的处理。
传统的方法是建立端到端的Text2SQL模型,通过语义理解用户的查询请求,并将其转化为可执行的SQL语句来获取所需数据。尽管这种方法取得了一定的效果,但也暴露出了明显的局限性:
为了解决上述问题,浩鲸科技积极探索将大型模型技术和数据分析工程化进行深度融合。借助大型模型强大的自然语言理解能力和公司在商业智能(BI)领域多年的经验积累,浩鲸科技实现了对话式的数据查询与快速分析,从而降低了用户获取和理解数据的难度。用户只需要简单描述自己的需求,系统就能迅速生成专业且美观的数据图表。据吴名朝介绍,浩鲸科技推出的鲸智ChatBI围绕“取数、看数、用数”的全流程,打造了智能意图识别、智能图表生成、智能数据推荐和智能数据洞察等功能,帮助用户构建易于使用的数据分析辅助工具,使企业用户能够像聊天一样,仅需一句话提问,即可轻松获得所需的数据分析结果,无需编写复杂的查询语句。
从技术实现的角度来看,基于语义理解的SQL生成任务需要精准理解用户的查询指标和相关维度。为了提高问数服务层的数据准确性和效率,浩鲸科技的BI大模型团队专注于构建一个全面的BI知识数据管理体系。
该体系涵盖了业务术语、同义词、原子术语、关键指标、多维数据及数据库表模型等核心要素的精细管理。这一措施旨在通过加深行业知识的嵌入来弥补基础大模型在垂直领域的知识不足,并加强上下文之间的精确关联,从而为大数据分析和用户决策提供更为坚实的信息基础。
通过整理和优化行业专用术语库,确保每个业务概念都能被准确表达。同时,建立了同义词管理系统,以解决自然语言处理中的语义模糊问题,使模型能够更好地应对各种语言表述方式。此外,对于关键性能指标和多维度数据的精细管理,浩鲸科技开发了一套高效的指标与维度数据管理体系,帮助用户深入挖掘数据价值,发现潜在的趋势与规律。
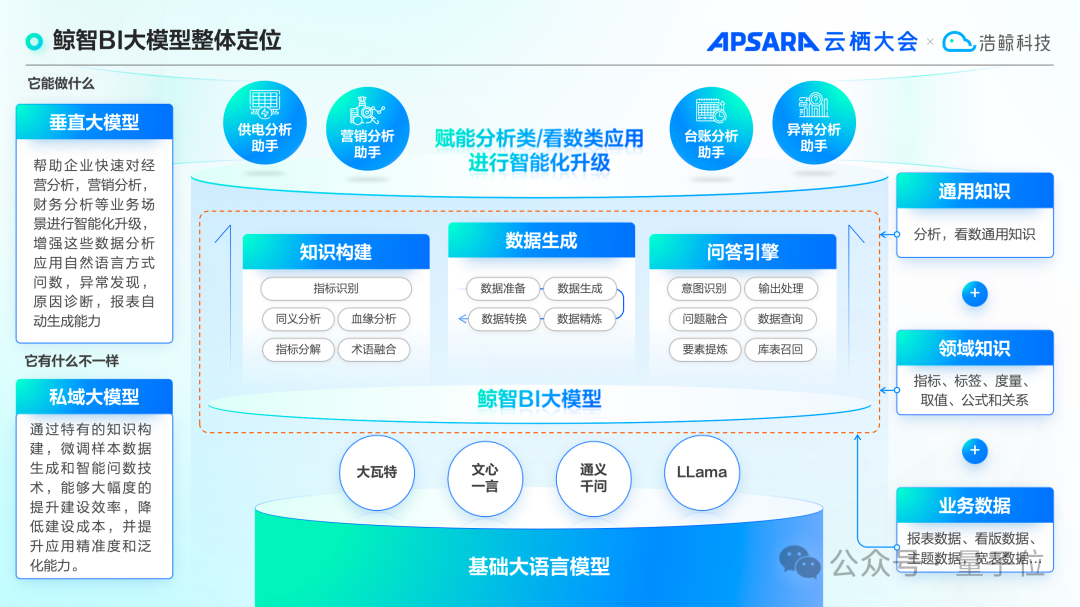
更为重要的是,通过库表模型数据管理的实施,为大模型注入了强大的结构化数据支持,这不仅提升了模型对复杂数据关系的理解能力,还赋予了其基于先验知识的推理与推断能力。这一过程实现了知识数据与大模型的深度融合与相互促进,使机器能更精准地理解人类语言的深层含义,并在实际应用中展现出更高的精准度与鲁棒性。
在BI问数的业务分析过程中,经常需要精确判断用户提及的指标是否涉及多个。面对用户描述模糊、意图表达不明确的情况,特别是在提问中包含了复杂的多主语、多层定语等结构时,通常需要先将这些提问细致拆解,然后进行准确的识别与合理的组合,以确保能够准确捕捉到用户实际想要分析的所有指标。处理用户查询时识别和处理多指标的难点主要体现在以下几个方面:

与许多开源方案相比,浩鲸科技的鲸智BI大模型进一步采用了知识召回模块和轻度弱化的Text2SQL整体架构。该模型旨在通过构建一系列高精度、高容错的RAG组件,降低大模型在垂直领域下实现复杂场景的难度,并最大程度地优化了Text2SQL的幻觉问题。
在BI问数的实践中,查询信息数据通常分布在多个维度表中,每个维度表都包含了描述数据的不同统计粒度或特有属性。
浩鲸科技首创融合虚拟视图技术,基于BI问数场景独有的数据分布特性,通过智能化方法整合查询过程中涉及的各种字段,包括但不限于维度字段、业务指标、度量值以及查询条件等,构建出一系列针对特定查询需求的临时视图作为大模型推理的基础依据。
这种“按需构建”的视图策略,使大模型推理信息中仅包含查询所必需的字段,不仅大幅减少了数据处理过程中的冗余信息,还提高了大模型的执行效率和精确度。
浩鲸科技的BI大模型专注于为特定业务领域量身定制并优化SQL生成模型。通过深度融合行业特有的数据库架构(包括库表结构)、业务逻辑中的语义信息以及海量数据等核心要素,该模型旨在生成最适合该行业的高效SQL查询语句。与广泛使用的Text2SQL模型相比,这一方案巧妙地利用了大型预训练模型对复杂行业语言模式的强大理解能力,并进一步通过精细化的业务数据资源进行微调,从而显著提升了模型将业务需求准确转化为SQL语句的能力,成功将行业相关术语的SQL正确转换率提高到92%的卓越水平。这一创新不仅代表了自然语言处理与BI数据库查询优化领域的深度融合和技术突破,更预示着在实际应用中,它能大幅提升业务系统的数据处理效率和准确性,为企业级用户提供前所未有的数据洞察能力和业务决策支持,堪称技术和应用双重价值并重的典范。
在发布会的最后,吴名朝表示:“BI大模型要完美融入实际场景还有很长的路要走,但我们愿意与行业伙伴和技术伙伴携手合作,共同攻克更多复杂场景下的应用难题。”