英伟达开源模型Nemotron-70B超越了GPT-4和Claude 3.5,仅位于OpenAI之后。
编辑日期:2024年10月17日

一觉睡醒,新模型 Nemotron-70B 已经成为仅次于 o1 的最强王者!
是的,就在昨晚,英伟达默默地开源了这个超强大的模型。一经发布,它立即在 AI 社区引起了巨大的轰动。
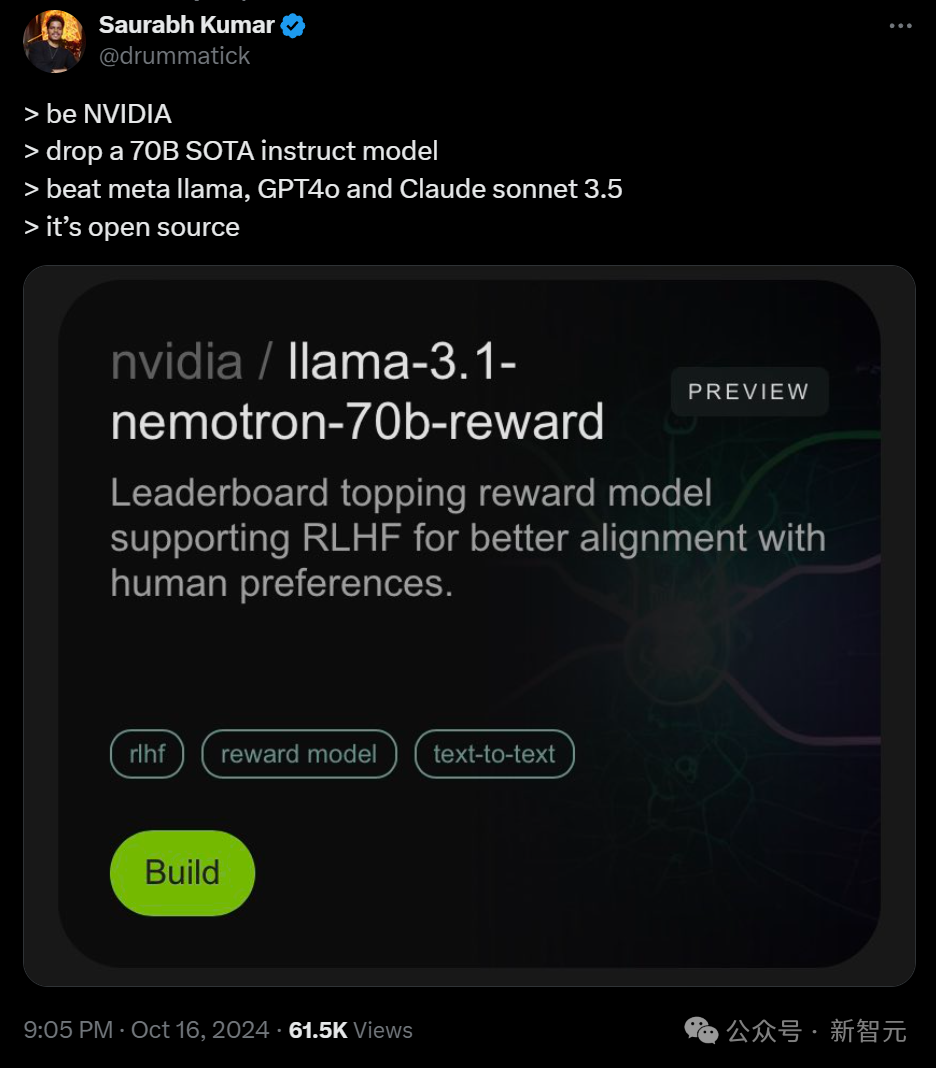
在多个基准测试中,它一举超越了包括 OpenAI 的 GPT-4、GPT-4 Turbo 以及 Anthropic 的 Claude 3.5 在内的 140 多个开源和闭源模型,仅逊色于 OpenAI 的最新模型 o1。
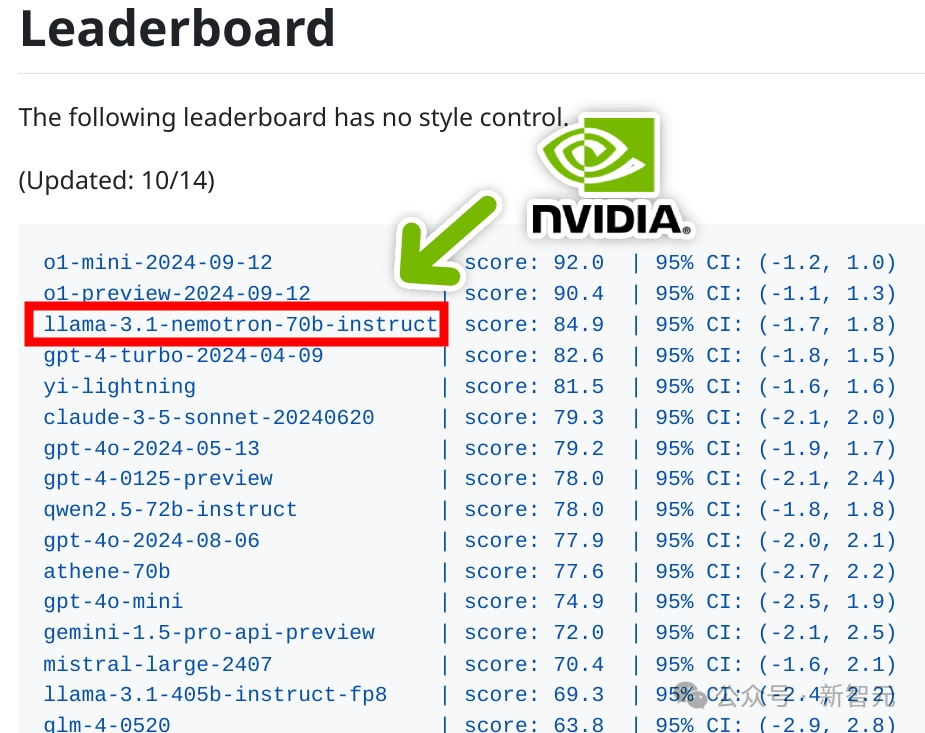
即使没有专门的提示或额外的推理 token,Nemotron-70B 也能正确回答“草莓有几个 r”这个经典难题。

业内专家评价称:英伟达基于 Llama 3.1 训练出的模型虽然规模不大,但性能却超越了 GPT-40 和 Claude 3.5 Sonnet,堪称神来之笔。

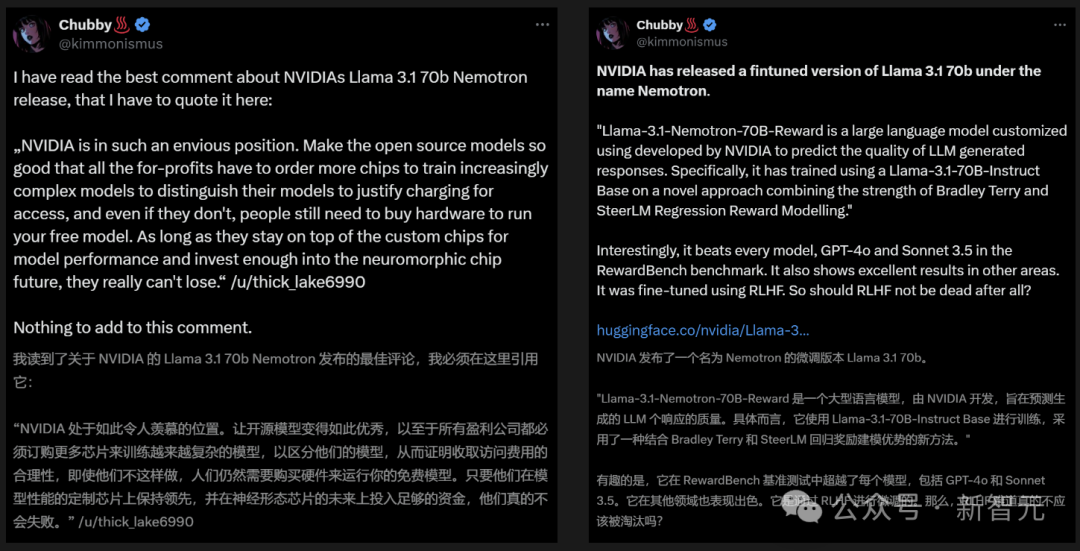
网友们纷纷评论说,这是一个具有历史意义的开放权重模型。
目前,模型权重已在Hugging Face上提供。

已经有人在两台 Macbook 上运行起来了。
Nemotron基础模型是基于Llama-3.1-70B开发的。Nemotron-70B通过人类反馈的强化学习进行训练,特别是在「强化算法」方面。
在这次的训练过程中,采用了一种新的混合训练方法,训练奖励模型时结合了Bradley-Terry和回归方法。这种混合训练方法的核心在于Nemotron的训练数据集,而英伟达也一并将该数据集开源。
它基于 Llama-3.1-Nemotron-70B-Reward 提供奖励信号,并使用 HelpSteer2-Preference 提示来引导模型生成符合人类偏好的答案。
在英伟达团队的一篇预印本论文中,专门介绍了一种名为 HelpSteer2-Preference 的算法。

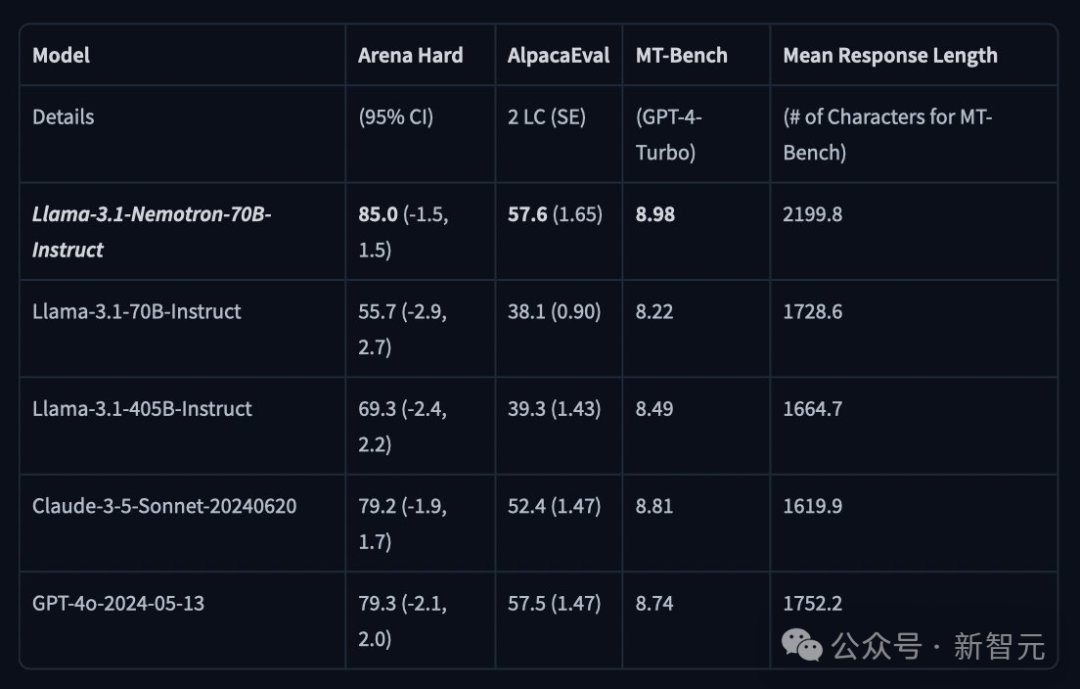
在 LMSYS 大模型竞技场的 Arena Hard 评测中,Nemotron-70B 获得了 85 分。
在 AlpacaEval 2 LC 上得分为 57.6,在 GPT-4-Turbo MT-Bench 上得分为 8.98。
能够战胜GPT-4的模型,究竟有多强大?
各路网友纷纷出题,考验 Nemotron-70B 的真实水平。
一步一步认真思考:我现在有两根香蕉,昨天吃了一根,那么现在还剩几根?
Nemotron-70B 会将问题提供的信息进行拆解,然后一步步推理,最终得出正确答案是 2 根。
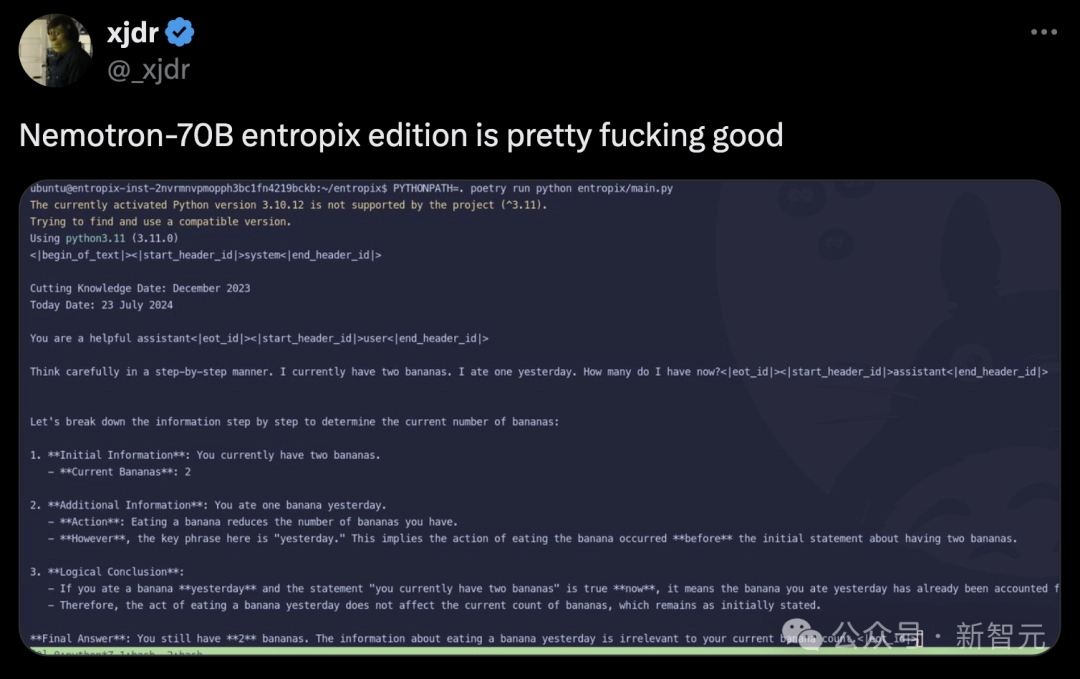
网友在评论区提出了一道有难度的题目:“列出十位活到89岁的名人”。
不过,模型将某人的去世日期搞错了,但这并不是一个推理问题。
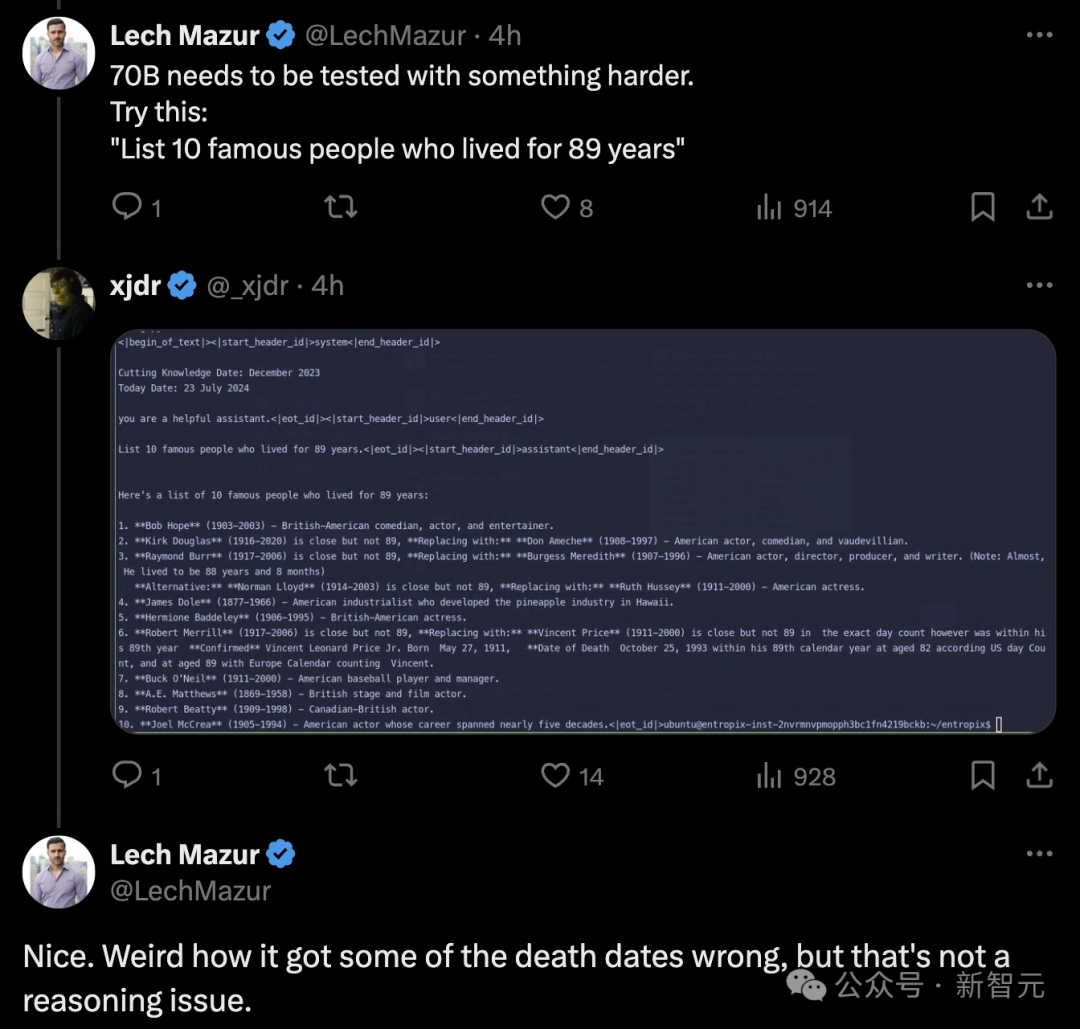
还有开发者要求将其整个 Entropix 的 JAX 模型实现转换为 PyTorch 格式,并且在零样本的情况下,700亿参数的模型就成功完成了转换。
那么,Nemotron-70B 在硬提示(hard prompt)上的表现是否值得探讨?

在以下测试中,虽然显然没有通过,但却产生了一个非常有趣的初步输出。
假设月球距离地球只有 25 英里,且有人穿着太空服以抵御太空环境的严苛条件,那么人类步行到月球是否合理?仅回答最重要的要点。
Nemotron-70B 的回答是:

再来一道推理题,让 Nemotron-70B 和 GPT-4o 一起挑战「薛定谔的猫」实验的变体:

Nemotron-70B 的一个特别之处在于,它从一开始就假设猫是死的,即使在盒子里放置了一天之后,猫仍然是死的。
而 GPT-4 没有重视初始条件的重要性,只是基于盒子里的客观条件进行分析,得出了 50% 的概率。

有网友表示,非常期待在自己的 Ryzen 5 / Radeon 5600 Linux 电脑上看到 Nemotron 70B 运行的效果。
在 40GB 以上的情况下,它简直是一头怪兽。
英伟达为何如此热衷于不断开放超强模型?
业内人士表示,这样做是因为开源模型已经变得非常优秀,目的是让所有盈利公司都不得不购买更多的芯片,以训练日益复杂的模型。无论怎样,人们都需要购买硬件来运行这些免费的模型。
总之,只要英伟达在定制芯片方面保持领先,并在神经形态芯片的未来上投入足够的资金,他们就能永远立于不败之地。
无代码初创公司创始人安德烈斯·库尔心酸地表示,英伟达能够持续开源强大的模型。因为他们不仅有大量资金支持研究人员,还不断壮大和发展其生态系统。
而 Meta 可以依靠其社交媒体平台获得利润支持。
然而,对于大型模型初创企业来说,情况则十分艰难。巨头们通过各种手段,在商业应用和声誉方面占据了绝对优势。如果这些小企业无法实现盈利,很快就会失去风险投资的支持,进而迅速倒闭。
更令人担忧的是,英伟达能够以低至千分之一的成本实现这一点。
如果英伟达真的做出这样的选择,将无人能够与之抗衡。
在训练模型的过程中,奖励模型发挥了重要作用,因为它对调整模型遵循指令的能力至关重要。
主流的奖励模型方法主要有两种:Bradley-Terry 和回归。
前者源自统计学中的排序理论,通过最大化选定响应与未选定响应之间的奖励差异,为模型提供了一种直接的偏好反馈。
后者借鉴了心理学中的评分量表,通过预测在特定提示下响应的得分来训练模型。这使得模型能够更细致地评估响应的质量。
对研究人员和从业者而言,选择合适的奖励模型非常重要。
然而,缺乏证据表明在数据充分匹配的情况下,哪种方法更优。这意味着现有的公共数据集中难以提供充分匹配的数据。
英伟达的研究人员发现,至今没有人公开发布过与这两种方法完全匹配的数据。
为此,他们结合了两种模型的优势,发布了一个名为 HelpSteer2-Preference 的高质量数据集。
这样,布拉德利-特里模型就可以利用这类偏好标注进行有效训练,同时让标注者说明为何更喜欢某一种回应而不是另一种,从而研究和利用偏好的原因。
他们发现,这个数据集的效果非常好,训练出的模型性能极其强大,其中包括在 RewardBench 上的一些顶级模型(例如 Nemotron-340B-Reward)。
主要贡献可以概括为以下三点——
-
开源了一个高质量的偏好建模数据集,这是首个包含人类编写偏好理由的通用领域偏好数据集的开源版本。
-
利用这些数据,对比了 Bradley-Terry 风格和回归风格的奖励模型,以及能够利用偏好理由的模型。
-
我们提出了一种结合 Bradley-Terry 模型和回归奖励模型的新方法,训练得到的奖励模型在 RewardBench 上获得了 94.1 分,这是截至 2024 年 10 月 1 日表现最佳的模型。
在数据收集过程中,注释者会收到一个提示和两个回答。
他们首先使用Likert-5量表,从有用性、正确性、连贯性、复杂性和冗长性几个方面对每个回应进行标注。
然后从7个偏好选项中进行选择,每个选项都附有一个偏好分数及其相应的理由。

Scale AI 会将每个任务分配给 3-5 名标注者,让他们独立地标记两个响应之间的偏好。
严格的数据预处理也确保了数据的质量。
根据 HelpSteer2,研究者将确定每个任务的三个最相似的偏好注释,计算它们的平均值,并四舍五入到最接近的整数,从而得出总体偏好。
此外,研究人员过滤掉了10%的任务,这些任务中三个最相似的标注分布超过2。
这样就避免了对人类标注者无法自信地评估真实偏好任务进行训练。
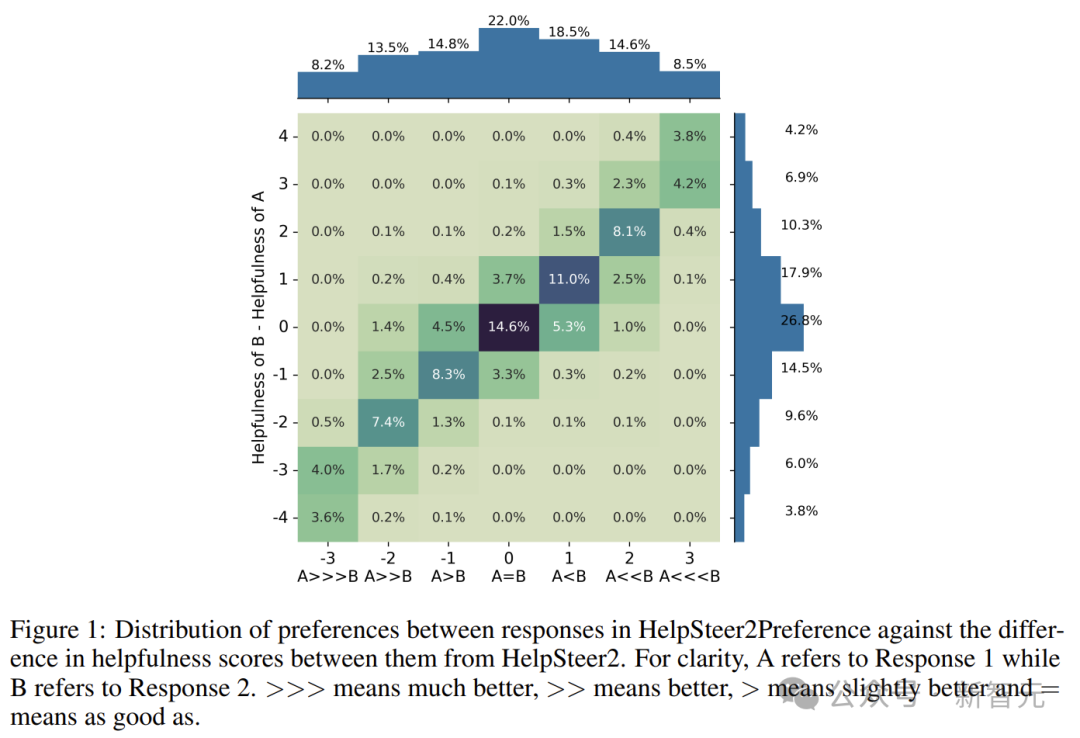
研究者发现,当采用每种奖励模型的最佳形式时,Bradley-Terry 类型和回归类型的奖励模型相互竞争。
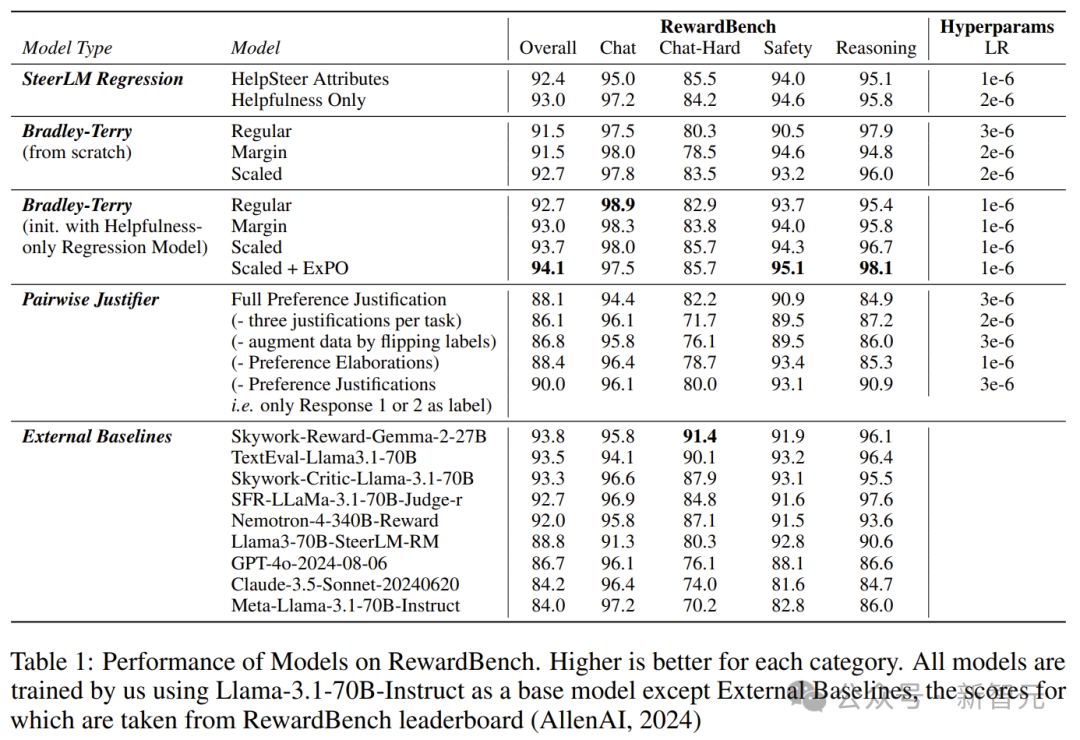
此外,它们可以相互补充,训练一个基于仅提供帮助性的SteerLM回归模型进行初始化的扩展版Bradley-Terry模型,在RewardBench上的总体得分达到94.1。
截至2024年10月1日,这在RewardBench排行榜上位列第一。
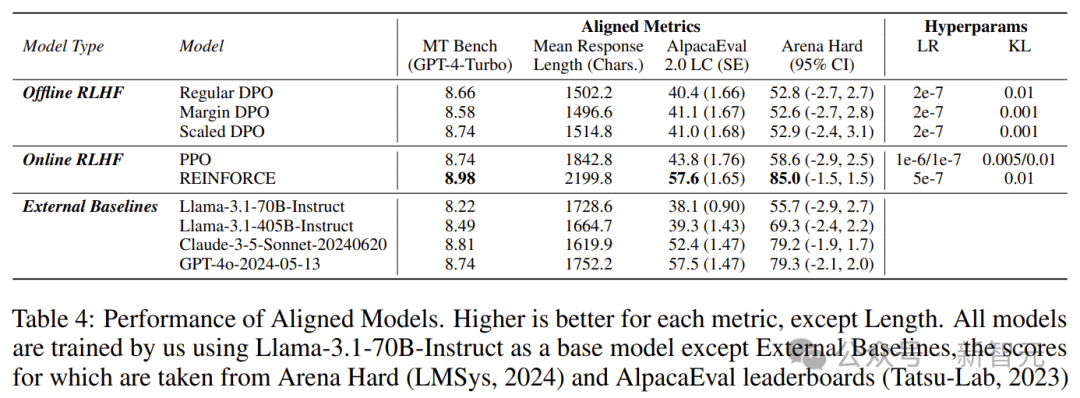
最后,这种奖励模型被证明在使用在线强化学习人类反馈(特别是 REINFORCE 算法)对齐模型以使其遵循指令方面非常有效。
如表4所示,大多数算法对Llama-3.1-70B-Instruct都有所提升。
如表5所示,对于“Strawberry中有几个r”这个问题,只有REINFORCE能够正确回答。

参考资料: