gpt4o-差点没及格首个多任务长视频评测基准它有亿点难

研究表明,多数模型的表现会在视频持续时间延长时明显恶化。
研究显示,增强上下文范围,提高图像解析能力,以及运用更为强劲的LLM骨干网络对于长视频理解的效能有显著的增强效果。
目前,相关的研究论文和数据集已经公开,详情如下,让我们一起来深入探讨吧!
目前,主流的Video Benchmark工具主要聚焦于短视频领域,这些视频的持续时间通常不会超过1分钟。
当前的评估标准常常局限于特定范围的视频,如电影或第一人称视角的视频,并且主要关注特定的视频评价任务,比如视频标题生成、时间感知或动作理解。
当前的许多长视频理解评估任务常常局限于单一的帧内容或者集中于对知名电影的问答,这使得MLLMs能够仅仅依靠文本提示就能准确回应,而无须真正解析视频内容。

针对上述的局限性,全新的MLVU基准从三个方面进行了精心构建:
MLVU的视频长度从短短3分钟延伸至超过两个小时,其平均视频时长达12分钟,这显著拓宽了现有流行Video Benchmark的时间跨度。
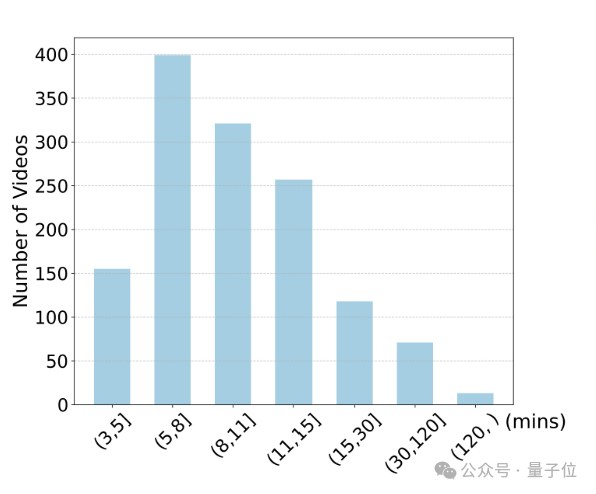
此外,MLVU 的任务注解大多涉及对片段与问题之间的对应关系进行详细标注。
比如,在Video Summarization的任务中,我们对视频的开头3分钟、6分钟等进行标定,只提供重述后的版本。
这表示MLLMs能够以灵活的方式在MLVU上评估不同时间跨度的长视频理解能力,从而只产生修订后的输出。
MLVU 涵盖了多样化的长视频资源,如电影、电视剧、纪实片、动漫、监控录像、第一人称视角视频以及游戏视频等众多类别,全面触及到长视频理解的各个专业领域。
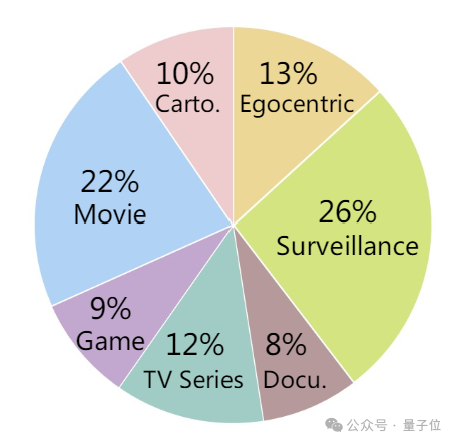
为了解析长视频,团队构思了九种独特的任务,并将这些任务系统地划分为三大类别:全面理解,专注于整体内容的掌握;单细节理解,侧重于对单一具体信息的把握;以及多细节理解,核心在于解析和理解多个复杂的细节。
要求模型全面掌握任务:这涉及让多模态语言模型(MLLMs)深入解析和有效利用视频的整体内容以解决问题,请仅提供改写后的版本。
任务阐述:目标是让多模态大型语言模型(MLLMs)能够针对问题精准地在长视频中寻找到相关细节,并基于这个细节提供问题解答,只需返回改造过后的答案。
多层面细节解析任务:这要求我们在大规模语言模型中精准定位并理解长视频中的各个关联片段,以便全面地解决问题,只需提供改写后的内容。
除此之外,评估内容涵盖了一元选择题与开放式生成问题,旨在全方位评估MLLMs在各种情境下的长视频理解效能。
以下是九个不同任务的范例:

以情节问答任务为示例,我们来着重展示新旧基准之间的差异。
如果采用电影或电视剧角色作为引导来构建问题向MLLMs提问,传统的评估标准通常涉及两种类型的问题。
首先,他们选择从“经典”内容入手,这使得MLLMs在没有对视频内容进行具体分析的情况下,依赖其内在的知识库来生成答案。
另一群人努力规避这一挑战,但由于长视频的丰富复杂性,仅凭代词和描绘性的语句来概括剧情细节显得尤为棘手。
他们的询问范围过于广泛,或者需要在问题中明确特定的时间区间,而非依赖于 MLLMs 从题目中自行识别相关细节。
MLVU 采用精准的手动标注方法解决了这些难题。
在所有的叙事性问答任务中,MLVU策略借助“详尽的代词”来指代故事中的角色、情节或环境,以此防止问题线索可能导致的潜在偏差。相反,MLLMs必须依据问题所提供的提示来寻找到相关的情节段落,然后才能进行后续的解答。
Furthermore, the MLVU's Plot QA questions exhibit a broad range of diversity, which significantly enhances the validity and reliability of the evaluation process.

我们的团队对 MLVU 平台上的二十款主流多语言学习模型进行了全面评估,这些模型涵盖了开放源代码和非开放源代码两类。
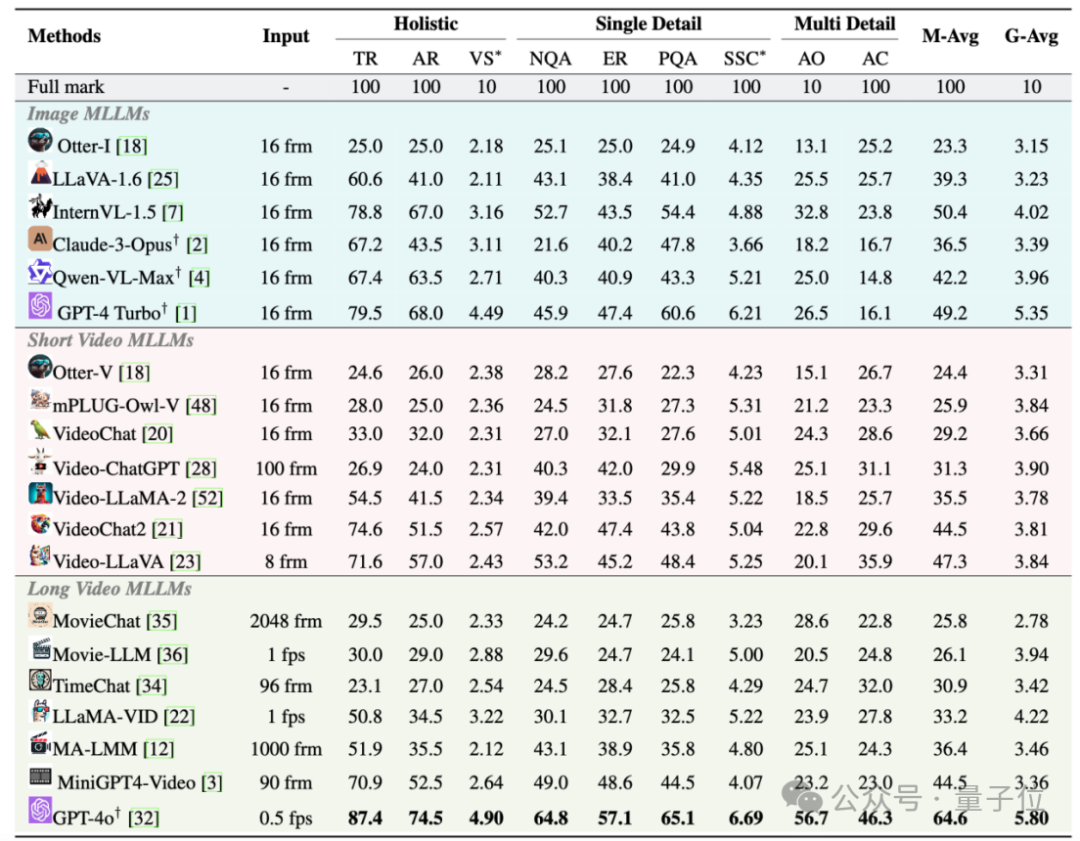
经实验数据证实,GPT-4o 虽然在各项任务中稳居榜首,但其选择题的平均正确率仅为64.6%,这表明仍有提升空间。
所有模型在要求精细理解能力的任务(不论是单一细节还是多重细节理解)中都显示出明显的不足。
而且,多数模型的表现明显会随着视频长度的增加而恶化。
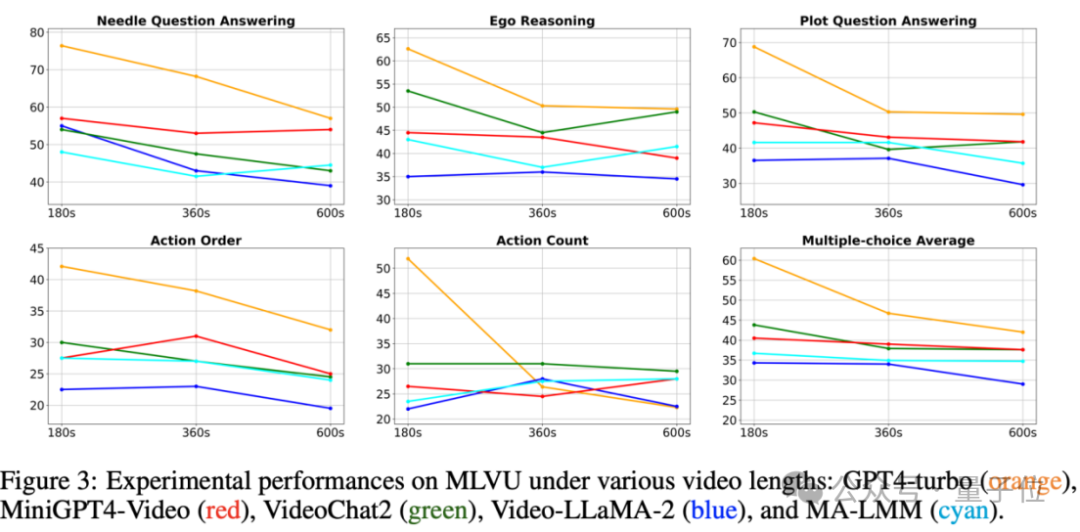
一个显著的洞察是,开放源代码模型和封闭源代码模型之间存在着显著的差异。
在开源模型的单项选择题领域,InternVL-1.5 的单选平均精度最高也仅为 50.4%,而在开放式的生成题目中,LLaMA-Vid 的表现最佳成绩只有 4.22,这些都显著低于 GPT-4o 所达到的 64.6% 和 5.80的水平。
然而,研究表明,扩大上下文范围能有效增强MLLM的图像理解能力,同时采用更先进的LLM骨干网络对长视频的理解性能有显著的提升。
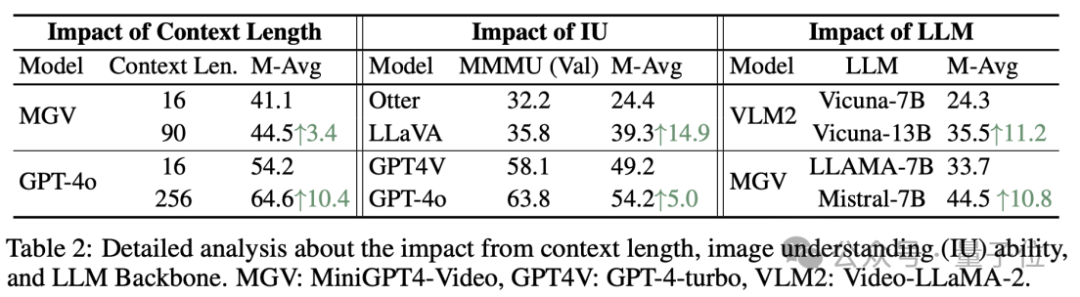
这指明了未来多模态预训练模型在增强对长视频理解能力上的关键优化领域。
论文:
项目链接:
原文来源:微信公众号量子位(ID:QbitAI),作者专注于探索最领先的科技动态
大家都在看
Python小白教程:点击学习
数据分析练习题:点击学习
AI资料下载:点击下载
大家在看