meta-推出基于-code-llama-的新型llm编译器专注于压缩代码体积反编译功能并且只提供重写后的代码结果全程采用中文沟通

Meta 已经在HuggingFace平台上发布了其7B和13B规模的LLM编译器模型,这些模型遵循开放的许可政策,不仅支持学术研究,同时也可应用于商业项目。
请查看以下链接:https://huggingface.co/collections/facebook/llm-compiler-667c5b05557fe99a9edd25cb,仅提供重写后的内容,始终以中文响应。
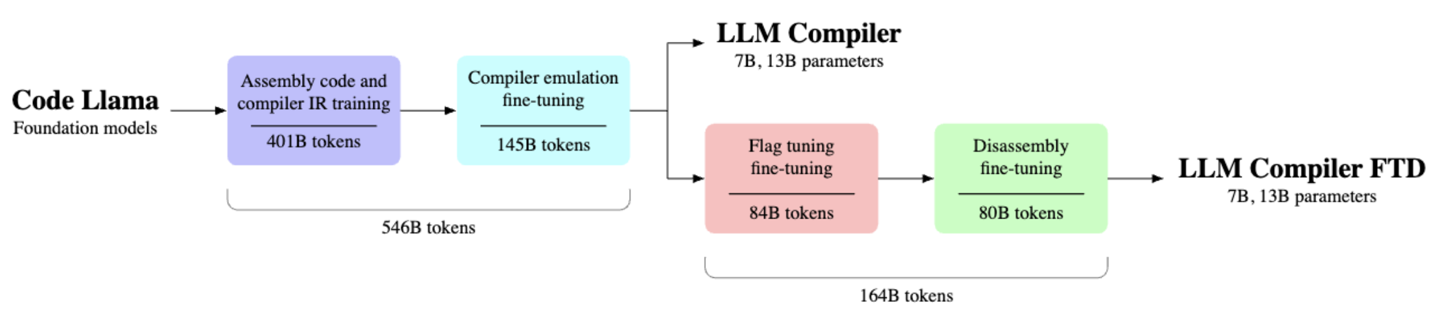
研究者在他们的论文中指出,LLM 已经在众多软件工程和编程任务中显示出潜力,但其在代码和编译器优化领域的潜力尚未得到充分挖掘。为填补这一空白,Meta 推出了 LLM 编译器,这是一个专门针对代码优化任务设计的预训练模型集合。
LLM 编译器模型是在一个庞大的语料库上进行训练的,该语料库包含5460亿个LLVM-IR和汇编代码标识,之后通过指令级微调来精确理解编译器的工作原理。其目标是为学术界和工业界的专家提供一个可扩展且经济有效的平台,以支持他们在编译器优化领域的深入研究和创新工作。
LLM 编译器在压缩代码尺寸方面展现出了卓越的成效。实验证明,该模型的优化能力可达到自动化调整搜索的77%,这不仅极大地减少了编译时间,还提升了各类应用程序的代码执行效率。
大家都在看
Python小白教程:点击学习
数据分析练习题:点击学习
AI资料下载:点击下载
大家在看

AI安装教程
AI本地安装教程

微软AI大模型通识教程
微软AI大模型通识教程

AI大模型入门教程
AI大模型入门教程

Python入门教程
Python入门教程

Python进阶教程
Python进阶教程

Python小例子200道练习题
Python小例子200道练习题

Python练手项目
Python练手项目

Python从零在线练习题
Python从零到一60题