








openai-把-gpt4-原始版给了瑞士洛桑联邦理工团队研究不微调只靠提示词能走多远
瑞士洛桑联邦理工学院(EPFL)的研究团队已获得许可,着手探究一个核心问题:“仅凭上下文学习是否足以使大型模型理解并执行指令?”
仅依赖提示词,不使用无监督微调、RHLF 或任何其他强化学习对齐技术,我们可以达到怎样的极限呢?
预训练的模型是否能够一蹴而就,转化为一个成熟的聊天机器人或AI助手呢?

如果能够实现,这将极大地简化类似ChatGPT的大模型的开发过程。
无微调对齐的技术,使得新诞生的预训练模型不再局限于单纯的“文本填充”任务,而是能够在提示词的引导下,掌握与用户交互、执行指令的能力,这一领域始终是业界研究的焦点。
当前的最先进的方法,被称为URIAL,源于艾伦研究所,该方法凭借系统提示词汇加上少量的风格样例,便能取得显著的成效。
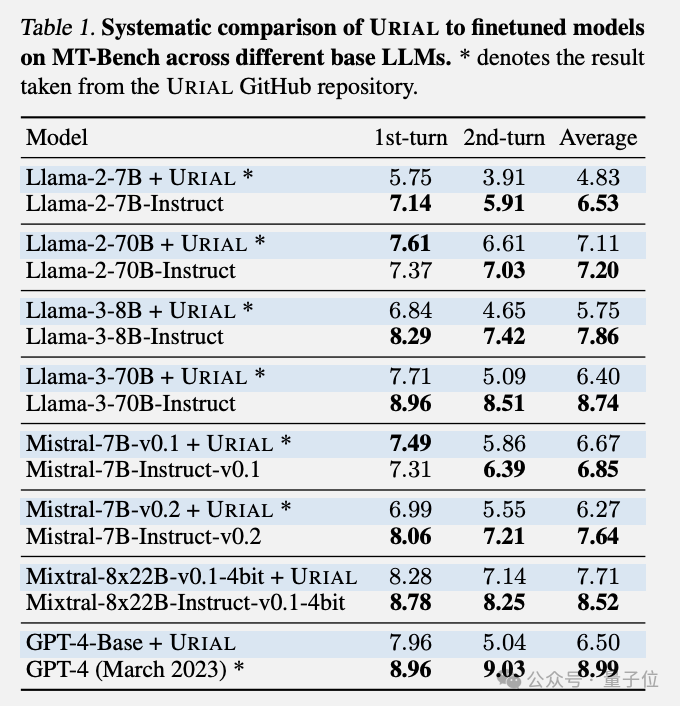
然而,EPFL 的研究团队指出,尽管 URIAL 在一定程度上缩小了与指令微调模型的差距,但它在多轮对话中的性能仍然不足。
这一现象在实验中被发现在Llama系列、Mistral系列以及极其罕见的GPT-4-Base模型中都存在。
我们已通过 OpenAI Researcher Access Program 获得了 GPT-4-Base API 的访问权限。
EPFL的研究团队着手探索各种策略,以期增强上下文学习的效能。
起初,他们尝试增加样例数量以期待改进效果,但遗憾的是,这样做并未显现出明显的性能提升,其表现并不像图像分类或机器翻译等任务那样,随着示例数量的增多而自然提升。
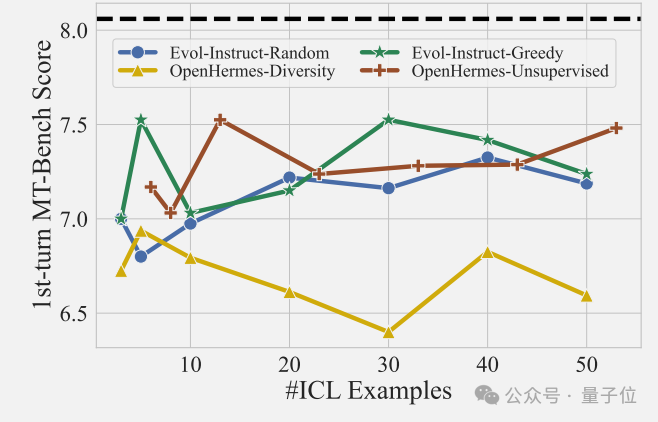
接着,他们应用了贪婪搜索策略,从众多实例中精心挑选出最优的一个来丰富上下文。
这种方法能够实现更优的性能提升,但仍未能完全弥补与指令微调模型之间的差距,尤其是在AlpacaEval 2.0评估基准上。
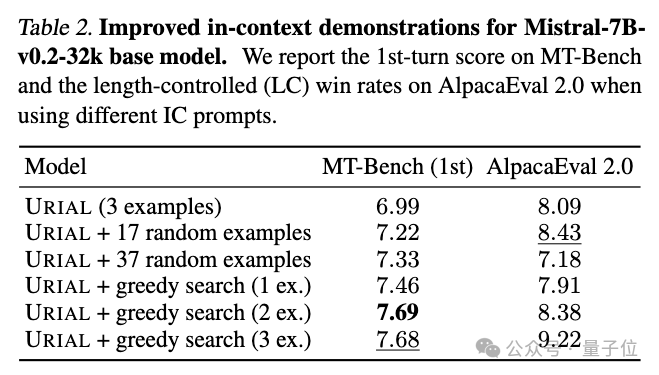
此外,他们还揭示了一个现象:贪心搜索在为一个特定模型优化出的最优样本,并不能稳定地迁移到其他模型上。
换言之,不同的模型对应着各自的适用案例。
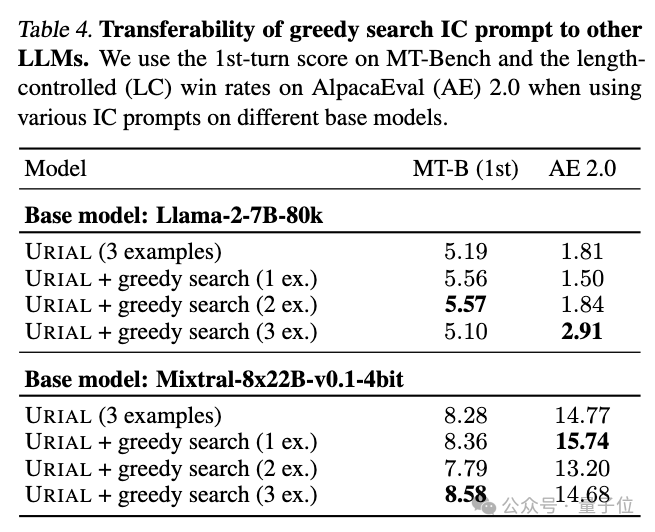
团队还开展了一系列的消除研究,通过移除或改变特定组件,探究这些变化对系统性能的影响,以此深化对上下文学习机制的理解。
他们在综合评估平台如MT-Bench上认识到,确保例子包含准确的“问题-答案配对”至关重要。
这与先前的观察截然不同,那时大型模型在分类任务中即便存在少量错误标签,只要拥有海量样本,依然能够正常运作。

因此,最后我们可以总结说:
研究结论指出,大型语言模型或许仅仅从上下文中习得了模仿示例回答的技巧,而并未真正掌握执行指令的内在逻辑。
指令遵循任务具有相当的复杂性和开放性,不容易被轻易掌握。
要让AI助手更加顺从,目前还很难找到简便的方法。
论文地址:
参考链接:
原文来源:微信公众号量子位(ID:QbitAI),作者:梦晨
大家都在看
Python小白教程:点击学习
数据分析练习题:点击学习
AI资料下载:点击下载

















