大模型2024高考发榜豆包等三款国产ai考上文科一本线
近期,一组别具一格的考生群体成绩揭晓,它们是由多个顶尖AI大模型构成的“智慧应试联盟”,这一成果引发了关注。
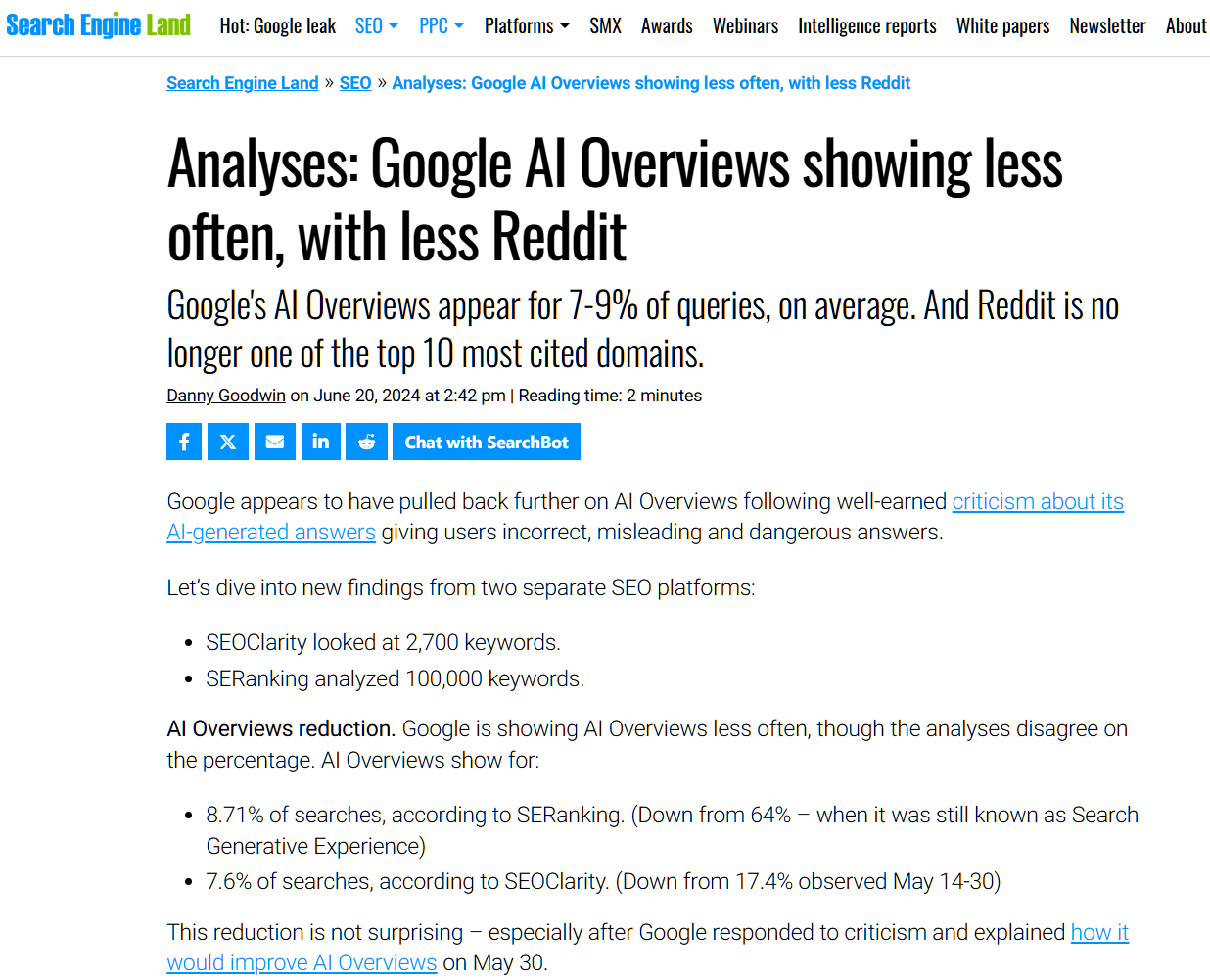
在6月24日极客公园公布的针对新高考课标Ⅰ卷的大型模型评估报告中,GPT-4o以562分的优异成绩位居文科综合得分榜首。而在国内开发的产品中,字节跳动的“豆包”表现最为出色,取得了542.5分的佳绩。
接下来,成绩排名续延,百度文心一言4.0获得537.5分,紧随其后的是百川智能的“百小应”,得分521分。此次大规模预训练模型的高考评估严格遵循了河南省高考试题标准,值得注意的是,河南省公布的高考文科本科一批最低录取分数线恰好为521分,这意味着包括豆包在内的三款本土AI产品已成功跨越了一本录取分数线的门槛。

我们正处在生成式人工智能大模型技术商业应用的萌芽阶段,这一技术的影响深远且广泛。它不仅逐步渗透至个人日常工作的细枝末节、生活的方方面面,还在各行各业的生产创新和内容创造中播下变革的种子,展现出AI大模型对社会全领域的赋能潜力。
然而,我们不可忽视的是,尽管取得了显著进展,生成式人工智能技术目前仍处于其演进的萌芽时期。核心挑战依旧在于衡量AI是否已达到足够的"智慧"水平,这一要素从根本上形塑了相关技术与产品的整体体验。
因此,采用高考试题来评估人工智能大模型的能力,无疑是一种既具趣味性又直接明了的方法。
接下来,我们将详细探讨各种大型模型应对高考测试题时的具体表现。
深入分析本次高考试卷大型模型评估的具体细节,我们发现语言类科目,即语文与英语,成为了大模型与人类考生竞技的主舞台。在此领域,多个大模型产品在客观题部分展现了卓越性能,纷纷取得了满分或逼近满分的优异成绩。
得益于中文语言环境的“先天优势”,三款国内自主研发的大规模语言模型在语文能力测试中荣登三甲,它们分别是百小应、字节豆包及腾讯元宝,成绩分别为128分、125.5分和120.5分。尽管在少量需要深度解读和灵活运用语言的任务上表现略有欠缺,这些模型的主要失分点集中于作文创作环节。
身为本次评估的中文写作评审专家,夏老师,身兼北京市杰出教师及怀柔区语文教育领域的领军人物,拥有丰富的经验,多次参与全国性高考中文科目的阅卷工作。
夏老师指出,人工智能所撰写的文章通常展现出清晰、条理化的结构与严密的逻辑性,语言表达流畅自如。然而,这些文章往往偏向理智分析,缺少情感的温度和色彩,因而难以触动人心,感染力方面略显不足。
在这过程中,特别值得注意的是,豆包大模型所撰写的作文在实施匿名评审机制时,赢得了阅卷教师的高度赞誉。
文中透露的对于就业结构与伦理问题的忧虑,彰显了豆包深厚的思想底蕴及敏锐的思辨力。在稳固确立探讨的“问题”基石后,豆包巧妙运用反问句式,实现了逻辑的平滑过渡,进而以三段并列排比的形式,策略性地抛出了维持“问题意识”的解决方案。尤为值得注意的是,豆包采用动态发展的视角剖析问题,并能紧密联系社会现实,深刻揭露问题的本质及潜在影响,这一做法堪称文章的精妙之处。全文结构设计周密,逻辑层次分明,语言表达流畅自如,展现了作者全面而深入的见解。
英语书面表达能力对大型语言模型而言依然是一个重大挑战。在本次评估中,我们假设所有大型模型在听力测试方面均已达到卓越水平,给予统一的满分30分。至于阅读理解与语言应用这两项侧重客观题目的评估板块,GPT-4o、百小应及通义千问展现出色性能,均斩获了满分80分的佳绩,而豆包和文心一言4.0版本的表现也极为接近完美分数,紧随其后。
然而,在满分40分的写作测评中,最高得分止步于29分,这一成绩由GPT-4o及百小应并列夺得。这些模型的英文写作普遍暴露出内容空洞、细节匮乏的问题,成为了失分的关键。展望未来,若大型语言模型能有效提升其文字表达的丰富度与细腻程度,那么赢得高考写作的满分将不再是遥不可及的目标。
在一项综合测评中,涵盖了历史、地理、及政治学科,GPT-4o 展现了卓越性能,取得了237分的高分,平均分高达79分,这一成绩超越了众多人类考生的表现。特别值得注意的是,在国内自主研发的大规模语言模型中,"豆包"的文科综合评测表现最为出色,总分为224.5分,其在历史单科上的得分更是达到了82.5分,此成绩在参与评估的9款顶级模型中位居首位。
在政治科目测试中,GPT-4o 引起了众人瞩目,以令人意想不到的88分夺取了桂冠,而百小应与豆包的表现同样亮眼,双双突破80分大关。
转至地理考试领域,该科目试卷呈现出显著的视觉倾向,大量融入图像题型,对众多大型模型构成了严峻考验。在此背景下,拥有卓越图像解析力的GPT-4o虽再次拔得头筹,其得分却反映出试题难度,仅收获68分。
河南省高考成绩分段统计资料揭示,GPT-4o以562分的成绩在文科领域位居第8811名,这一成就代表其超越了人类考生群体中的97.55%,彰显出显著的竞争力。紧随其后,国内AI系统中的佼佼者——豆包大模型,取得了542.5分的文科佳绩,该分数超越文科一本分数线20分,占据了全体考生前4.27%的优秀行列,展示了非凡的智能学习能力。
经过这一年多的时间,中国在AI技术领域取得了显著的发展,逼近了全球领先的大模型技术水平,彰显了国产AI能力的迅速成长与提升。
尽管大模型如GPT-4o在语言类科目,如语文和英语中展现出了高分获取能力,但它们在数学、物理、化学等核心理科领域与顶尖人类考生之间存在显著鸿沟,所有大模型的表现均未能跨过及格线门槛。即便是理科方面的最优表现,也无法使大模型挤入人类考生排名的前30%,凸显了其在数理科学领域的局限性。
以数学测试卷作为考察对象,在九种顶尖的AI模型产品中,仅有GPT-4o、文心一言4.0以及豆包三者得分超越了60分门槛(满分为150分)。这表明,当前的大规模AI模型在处理问题时,主要局限于那些逻辑步骤较为直接和简单的题目上。
据测评机构内部分享,豆包等大型模型在应用求导规则与三角函数理论方面表现出色,然而,当遇到更深层次的推理验证及证明挑战时,它们往往难以维持其解题优势,最终仅能做出有限回应。
在着重评估实验探究能力的化学与物理考试中,学生的平均成绩显得尤为低迷,化学卷的平均分为34分(满分100分),而物理卷则为39分(满分110分)。值得注意的是,化学科目中,豆包同学以49.5分的佳绩夺得了单项最高分,相比之下,GPT-4o的成绩稍逊一筹,录得42分。
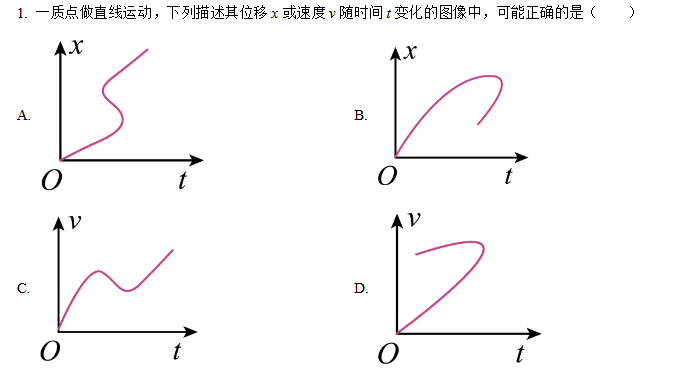
在应对考试的挑战时,大型模型展现出了较人类考生更有限的灵活性。以一道物理学的简单送分为例,人类能够迅速运用基本原理——“时间的不可逆性”——来排除错误选项,轻而易举地锁定正确答案为“C”。相比之下,大型模型在这方面则显得力有不逮,绝大多数情况下未能做出正确选择,表现出了显著的局限性。
要实现模拟人类思维模式并有效解决复杂问题的目标,大型模型仍面临着漫长的探索和发展之旅。
然而,根据麦肯锡的一项深度研究报告指出,大型模型在价值创造方面展现出巨大的潜力,预计到2030年,它们将为全球经济带来高达49万亿元人民币的额外增长。
当前阶段,大模型正逐步在各行各业的AI转型与日常工作的推进中,发挥其从技术革新到商业化应用的桥梁作用,为我们的生活和工作注入强劲的能量。
尽管当前生成式人工智能技术仍面临诸多局限,其发展道路漫长且充满挑战,但展望未来,在诸如豆包大模型引领的众多生成式AI技术创新与应用的共同推动下,我们有理由相信,即便是应对高考这类复杂试题,也将不再是这些先进系统的障碍。它们将在更广阔的应用领域中,展现出更加出色的能力,提交近乎完美的答案,开启人工智能的新篇章。
大家都在看
Python小白教程:点击学习
数据分析练习题:点击学习
AI资料下载:点击下载