








手机流畅运行-470-亿大模型上交大发布-llm-手机推理框架-powerinfer2提速-29-倍
当前,应用于移动设备的模型规模相对较小,如苹果的3B参数量和谷歌的2B参数量,然而这些模型却需要大量的内存,这显著制约了它们的实际应用范围。
即便像苹果这样的公司,目前也得依赖与OpenAI的合作,将强大的GPT-4云模型整合进其操作系统,以此来增强服务功能。
因此,苹果的混合策略引发了大量有关数据隐私的辩论和争议,连埃隆·马斯克也参与了进来。

既然在手机上本地部署大型AI模型能让用户在享受高级智能的同时,还能确保个人隐私的安全,那么苹果为何仍选择与OpenAI合作,采取云端大模型,从而可能面临侵犯隐私的隐患呢?关键的难题主要涉及两方面:
针对上述难题,上海交通大学的IPADS实验室推出了一款专为智能手机设计的大型模型推理引擎——PowerInfer-2.0,相关论文目前已在arxiv平台上公开。

PowerInfer-2.0 系统能够在内存资源有限的智能手机上实现高效的推理运行,使得Mixtral 47B模型在这样的设备上也能达到每秒处理11个令牌的出色速度。
与广泛采用的开源推理框架 llama.cpp 相较,PowerInfer-2.0 在推断性能提升方面展现出显著优势,平均增益可达25倍,最高峰值甚至达到29倍。
为充分发挥PowerInfer-2.0框架的潜能,上海交通大学的研究小组近期推出了创新的大模型优化方案——Turbo Sparse。这项技术的相关论文已公开发表在arxiv上,且已在业界引起了广泛关注。
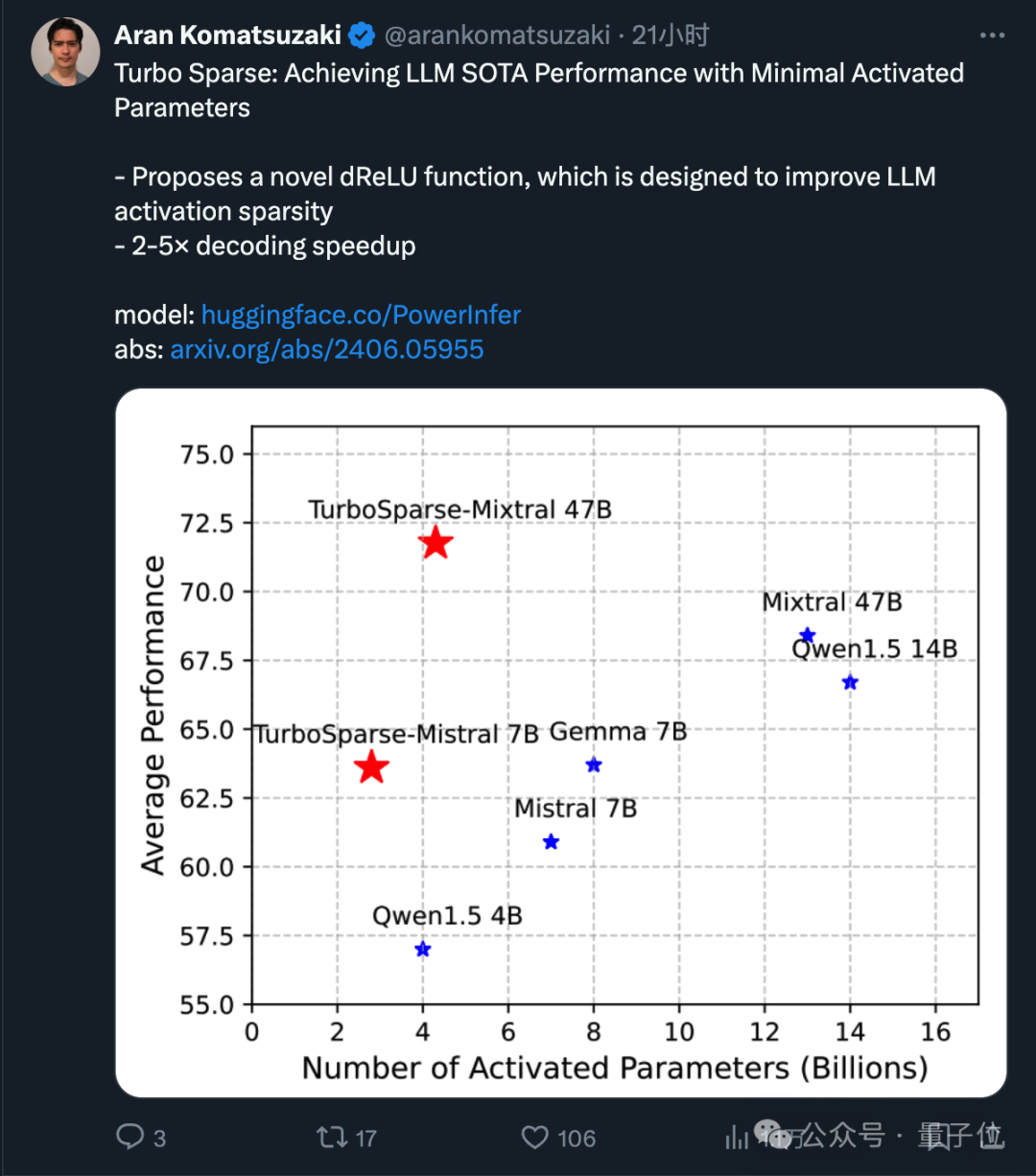
此外,值得一提的是,上海交大研究团队在去年底推出了针对个人计算机环境的高效推理系统——PowerInfer-1.0。这个框架在常见的消费级显卡如 4090 上,成功实现了对 llama.cpp 的速度提升,最高可达 11 倍之多。它在 GitHub 热门榜上连续霸榜三天,并在短短五天内收获了 5,000 个星标,目前其受欢迎程度已攀升至 7,100 个星标。
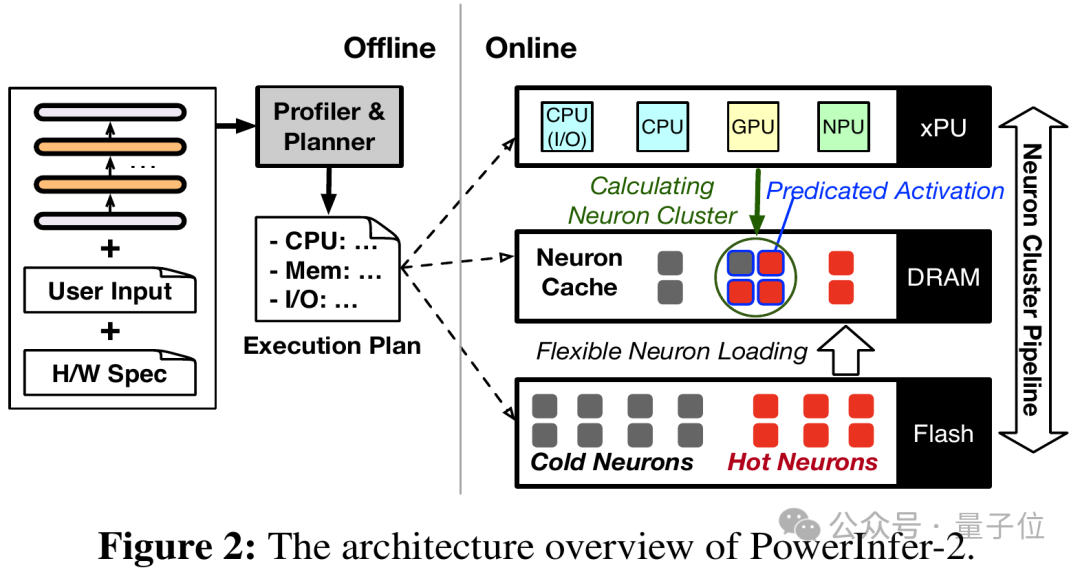
针对手机设备内存和计算能力的局限性,PowerInfer-2.0 是如何巧妙地优化以提升大型模型在移动端的推理速度呢?
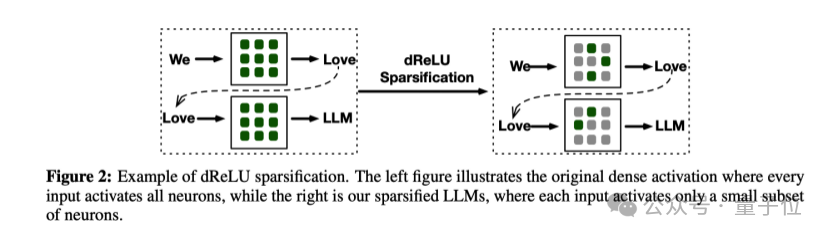
针对手机内存(DRAM)紧张的情况,PowerInfer-2.0 着眼于一个关键的策略:在执行稀疏模型推理时,仅激活部分神经元,这被称为“稀疏激活”。未被激活的神经元在AI模型推理过程中无需参与计算,而且这种缺席并不会对输出结果的精度产生负面影响。
稀疏激活技术为减少模型推断阶段的内存消耗开辟了新的可能性。为了充分挖掘这一特性的潜力,PowerInfer-2.0 将神经网络中的神经元划分为活跃度较高的“热”神经元和较低的“冷”神经元两类。系统运用 LRU(最近最少使用)策略在内存中维持一个神经元缓冲区,确保高效利用资源。
最近活跃的“热神经元”常常驻留在运行内存中,而相对不活跃的“冷神经元”则在预测到需要激活时才被调入内存,这样显著减少了内存消耗。
实际上,冷热神经元的划分策略是沿用了PowerInfer-1.0先前的实践。
去年12月,苹果在“LLM in a Flash”项目中推出了与神经元缓存相似的“滑动窗口”技术,专注于终端侧的大语言模型推理。然而,这些解决方案主要面向个人计算机平台,若要将其无缝移植到移动设备上,将面临一系列新的挑战。
首先,移动设备的硬件配置与PC相比有着显著的不足,无论是计算能力、内存容量还是存储带宽,都明显不如PC。
其次,智能手机硬件平台包含了CPU、GPU和NPU这三种结构各异的计算模块,其复杂性不言而喻。各硬件厂商在宣传时常常会突出总的计算能力,这通常是将CPU、GPU和NPU的算力相加得出的结果。然而,当实际运行大型模型时,是否能有效地利用这些不同架构的算力却是一个待解的问题。
针对这一需求,PowerInfer-2.0 模型将大规模的粗略矩阵运算精细划分为"神经元群"的微小计算单元。
每个神经元集合可能由多个参与运算的神经元构成。针对不同的处理单元,会依据其独特性质灵活地确定神经元集合的规模。
比如,NPU 在执行大规模矩阵运算时表现出色,我们能够将众多神经元整合为一个大型的神经元集合,整体交由NPU进行处理,以此最大化地利用其计算效能。然而,当运用CPU时,我们可以将神经元拆分成多个小规模的集合,分散到多个CPU核心中并行计算。
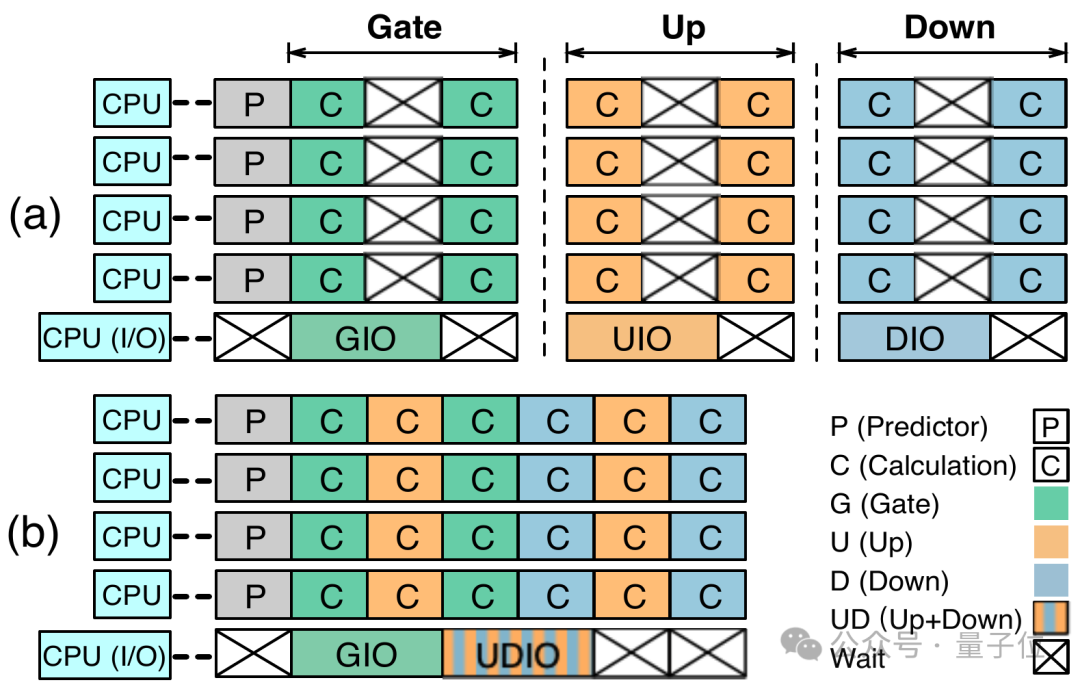
具体来说,PowerInfer-2.0 针对模型推断的预填充步骤(Prefill)和解码步骤(Decoding)各自提出了独特的神经元簇划分策略:
预填充步骤会大量引入令牌,大多数神经元因而会被激活。鉴于这种情况,我们倾向于选用大型神经元集合交由NPU进行计算。与此同时,CPU并不闲置,它在后台忙碌地执行着模型权重的反量化任务。
在解码步骤中,由于每次处理仅涉及一个token,其特性高度稀疏,因而更适宜将其细分成多个小规模的神经元集群,交由CPU进行灵活的调度和运算执行。
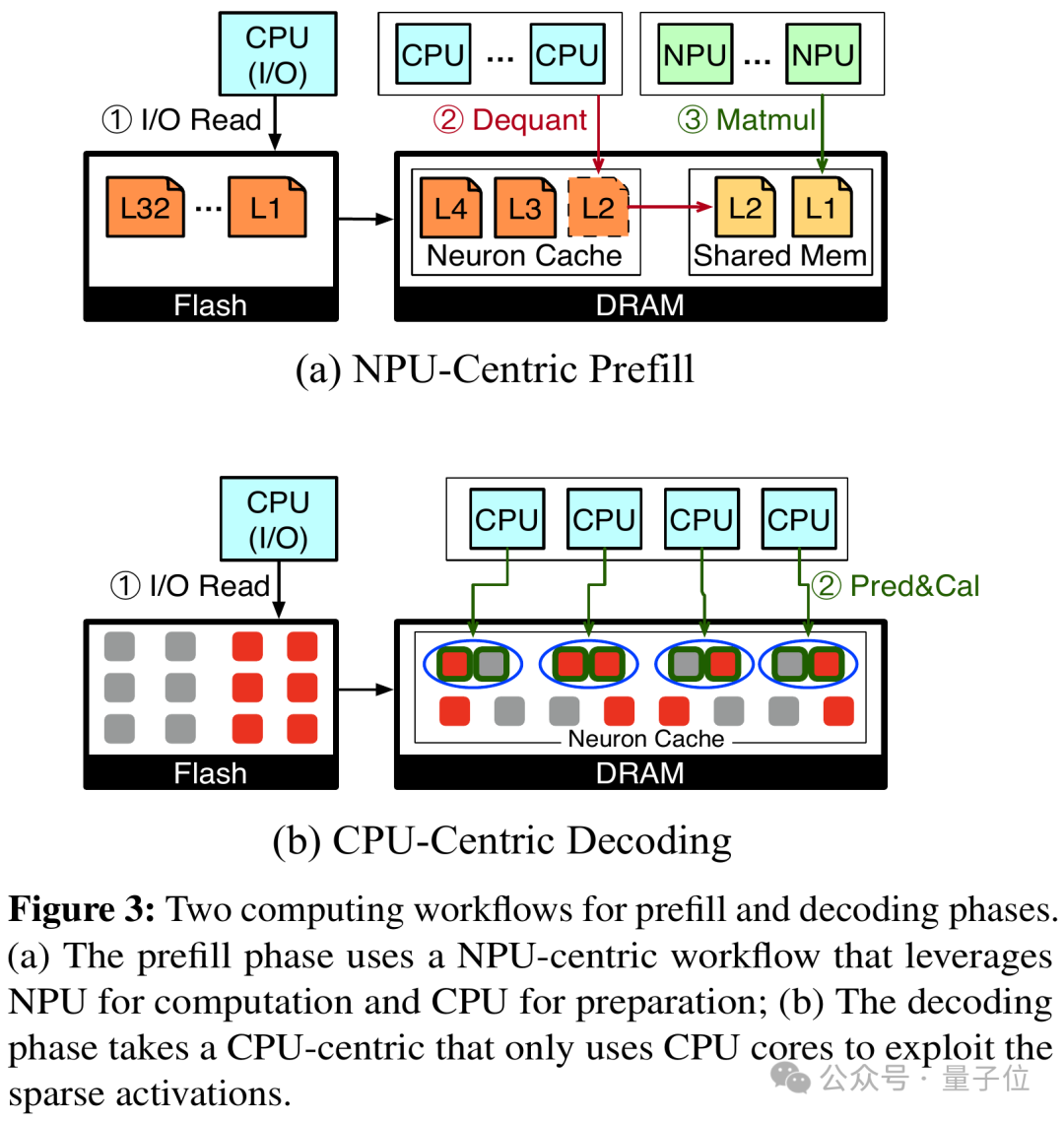
神经元簇的概念不仅能够更有效地适应手机中异构计算的需求,还天生具备支持计算和存储I/O的并行流水线处理能力。
PowerInfer-2.0 研发了分阶段神经元缓存及神经元群集级的流水线策略。这一创新使得当一个神经元群在等待输入/输出操作时,系统能迅速调度预处理好的其他神经元群到处理器中执行计算,有效地掩盖了I/O操作的延迟影响。
此外,这种以神经元簇为根基的流程设计颠覆了传统推理引擎按矩阵顺序运算的模式,使得不同参数矩阵的神经元簇能够交错运作,从而实现最大限度的并行处理效能。
模型推理过程中,神经元的I/O加载速度同样举足轻重。
针对各种权重类别,如注意力权重、预测器权重和前馈网络权重,分段缓存采用差异化的缓存策略,以优化缓存效率,降低不必要磁盘I/O操作的发生,从而提升性能。
缓存运用LRU替换策略,实时调整每个神经元的热度状态,确保缓存始终保存着最高频使用的神经元。同时,PowerInfer-2.0针对智能手机UFS 4.0存储的特性,定制了一种优化的模型存储布局,以提升读取效率。
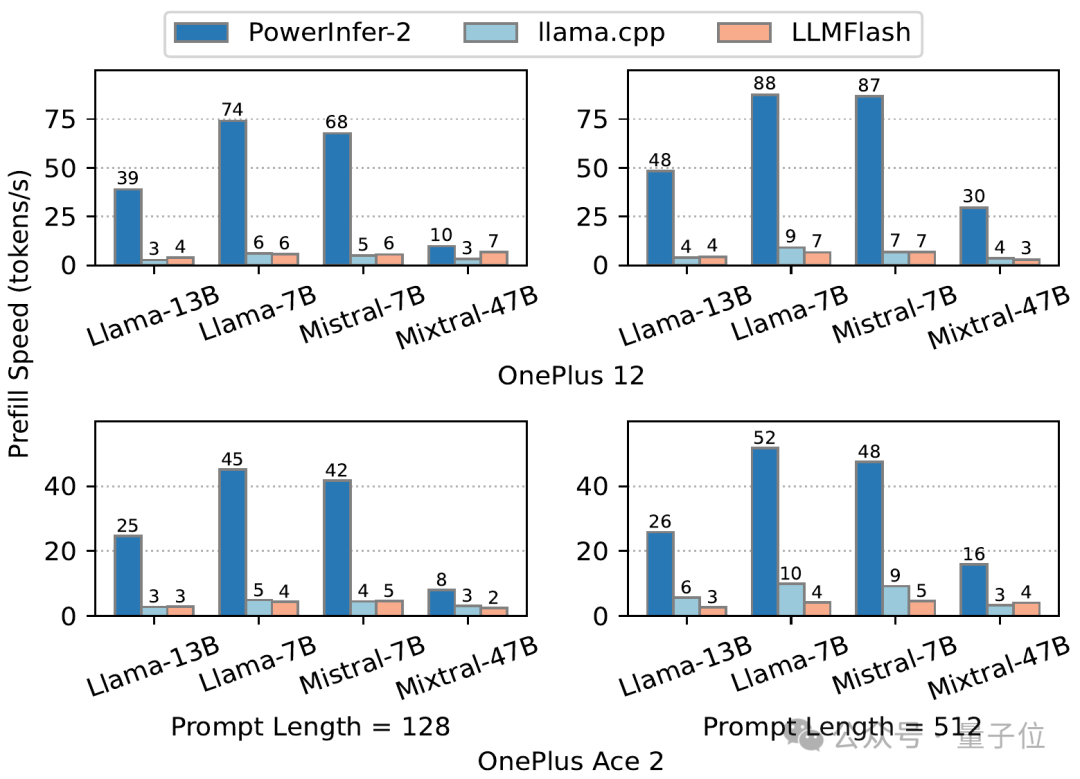
最后,我们来看看实际的测试表现。在一加 12 和一加 Ace 2 两部测试手机上,当内存资源有限时,PowerInfer-2.0 的预加载速度明显优于 llama.cpp 以及 LLM in a Flash(我们简称它为“LLMFlash”):
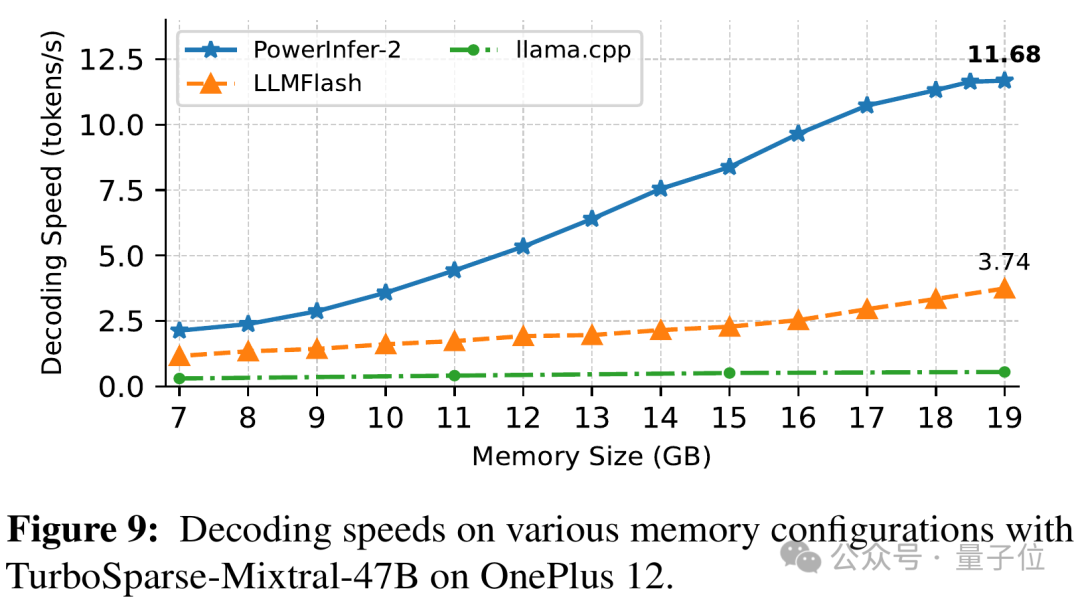
PowerInfer-2.0 在解码阶段也展现出显著的优势。尤其是面对Mixtral 47B这样的大型模型,它仍能在手机上实现11.68 tokens / s的高效运行速度。
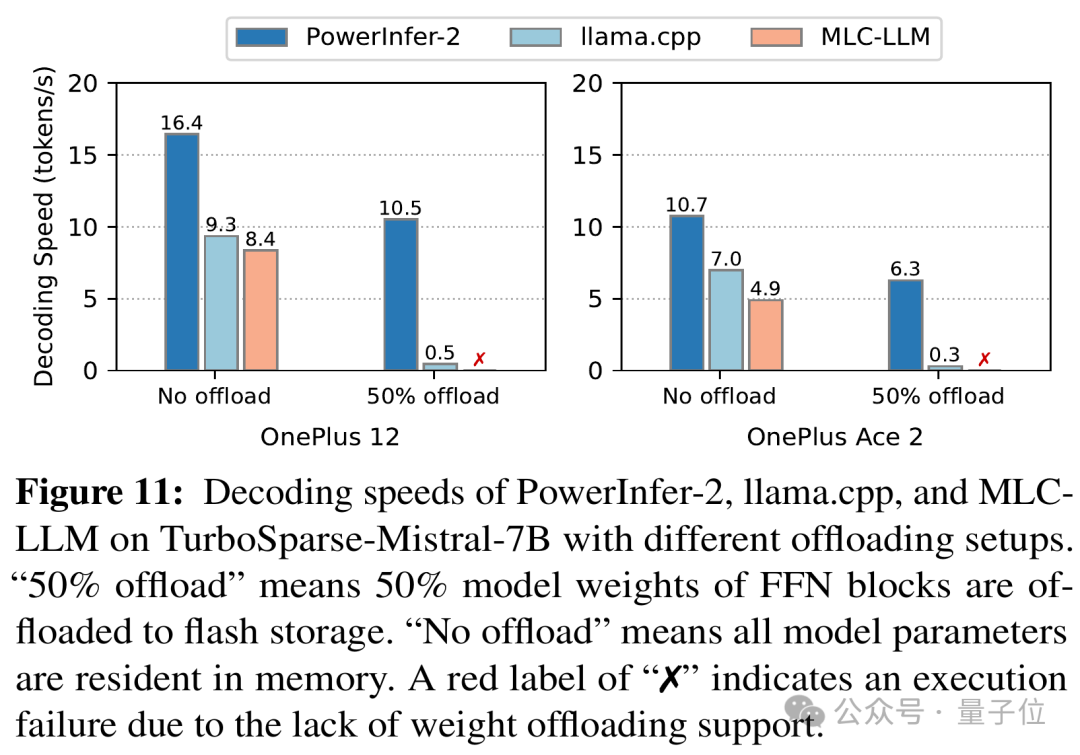
对于能够适应手机运行内存的Mistral 7B模型,PowerInfer-2.0在降低40%内存消耗的同时,实现了与llama.cpp和MLC-LLM相当甚至更优的解码速度。
PowerInfer-2.0 是一种创新的模型与系统联合设计策略,它要求模型具备能够预判和处理稀疏性的能力,以实现更高效的协作。
如何在有限的成本下优化模型以适应PowerInfer-2.0框架,同样是一个重大的难题。
传统的简单ReLU稀疏化方法往往会对模型的原始性能产生显著影响。
为解决这一难题,上海交通大学的IPADS团队携手清华大学及上海人工智能实验室创新性地提出了一种经济高效的稀疏化策略,该策略能显著提高模型的稀疏程度,同时确保模型保持原有的效能。

首先,该论文对模型稀疏化过程中所面临的问题进行了深入探讨。
在 LLaMA 类模型中单纯地添加 ReLU 激活函数虽然可以引入一些稀疏性,但这种稀疏性仍然是较为有限的。
由于训练数据的稀缺性和训练词汇的局限性,稀疏化处理常常引发模型准确性的降低。
为提高模型的稀疏性,该论文引入了一种名为dReLU的新激活函数,它是在ReLU的基础上构建的。通过替换原始激活函数并持续进行预训练,这种方法有效地增强了网络的稀疏结构。
将 SwiGLU 换成 dReLU 不仅直观地提升了输出中零值的比例,同时在稀疏化过程中更高效地利用了预先训练好的 gate 和 up 矩阵权重,实现了有效复用。
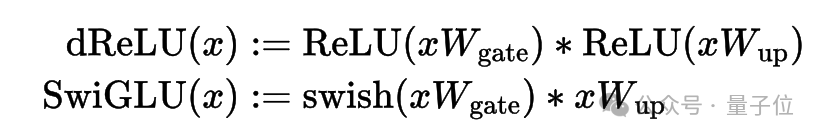
为了解决模型效能减弱的挑战,团队汇集了一个丰富的持续训练数据集,涵盖了网页内容、编程代码和数学资料等多种来源。这种高质素且多元化的训练数据有助于模型在进行稀疏化处理后,依然能保持甚至提升其效能。
最终,团队运用了 TurboSparse 技术来训练两个庞大的模型以进行验证,这些模型的规模分别为 8x7B 和 7B。由于采用了优质的持续训练数据,TurboSparse 系列模型的精度竟超越了原始模型(详情参见表 6)。
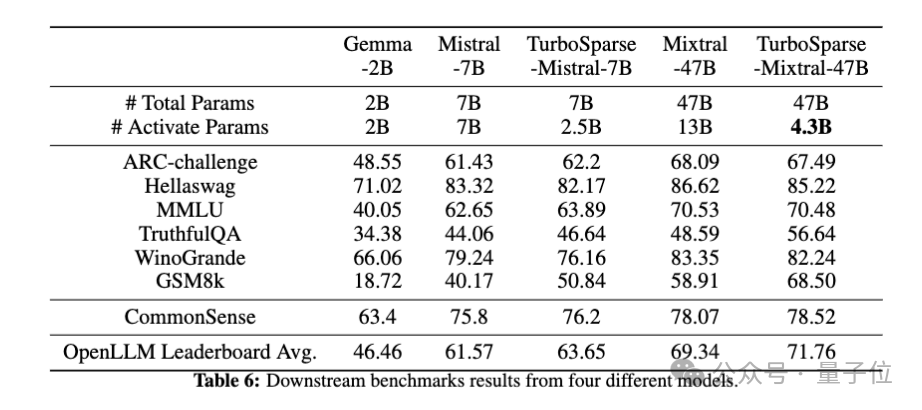
在稀疏性方面,TurboSparse-Mixtral 模型展现出了卓越的成效。相较于原始的 Mixtral 模型,其需要激活的参数量从13B大幅减少至4.3B,这意味着TurboSparse-Mixtral 激活的参数量仅为原模型的三分之一。
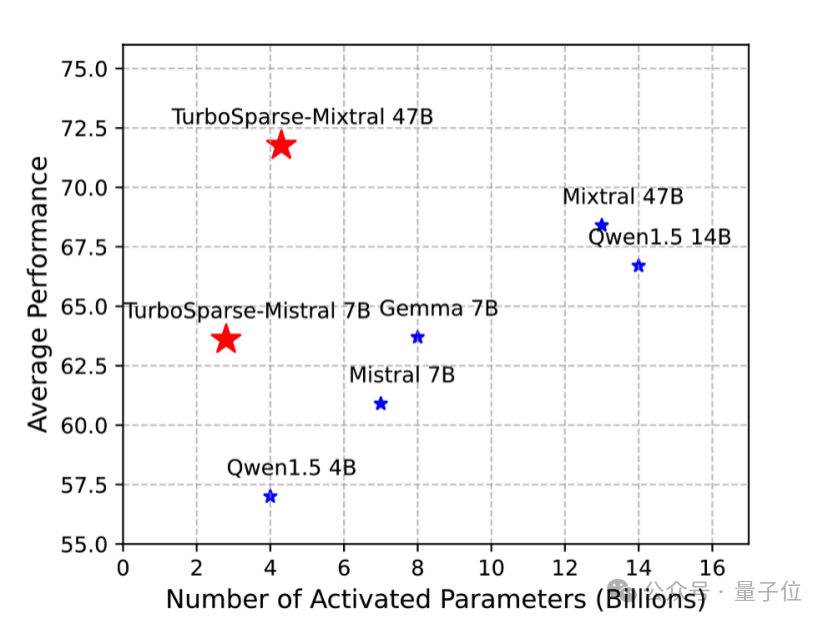
对于稀疏化操作的代价,根据 TurboSparse 文献的阐述,该转换期间模型需额外训练 150B 个令牌,相较于预训练阶段(假定为 3T 个令牌)仅占不到 5% 的比例,这表明其成本是相当低廉的。
上海交大的研究团队在推理策略和模型优化两个层面取得了突破,成功地使大型语言模型能够在手机等资源有限的环境中实现高效运行。
这套方案的影响力不仅仅局限于智能手机领域,它在未来的车载系统以及智能家居等应用场景中,还蕴藏着巨大的发展潜力。
最后,让我们正式揭示团队风采。上海交通大学的并行与分布式系统研究所(IPADS)在陈海波教授的引领下,汇聚了13位杰出教员和超过100位才华横溢的学生。
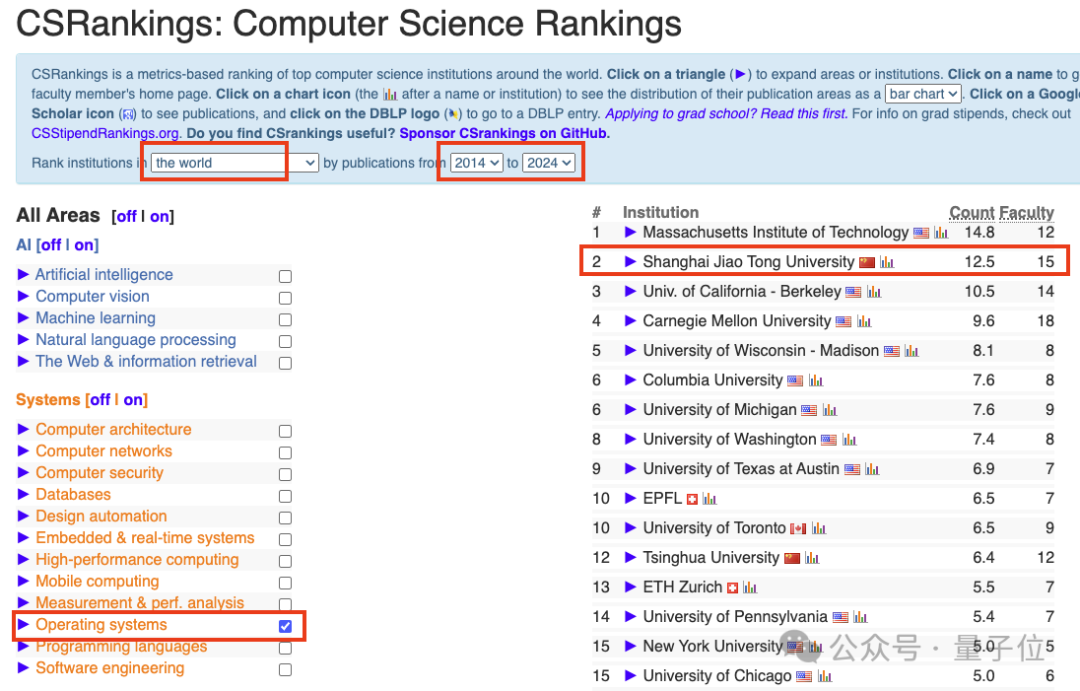
IPADS 在计算机系统领域拥有深厚的钻研历史,过去十年间,根据权威的 CSRankings 榜单,其在操作系统方面的研究稳居世界前二,仅次于麻省理工学院(MIT)。值得一提的是,上海交通大学是这份全球前十榜单上唯一的亚洲高等教育机构。
当前,上海交通大学的IPADS团队已在Huggingface平台上发布了其稀疏模型权重。展望未来,如果PowerInfer-2.0能与智能手机制造商建立更深入的合作关系,无疑将有力推动相关技术从研究环境迅速应用于实际生活中的各种场景。
大家都在看
Python小白教程:点击学习
数据分析练习题:点击学习
AI资料下载:点击下载

















