






研究发现openai-的-gpt4o-道德推理能力胜过人类专家
据 The Decoder 周六的报道,研究人员来自美国北卡罗来纳大学教堂山分校及艾伦AI研究所,他们开展的两份研究表明,他们对比了GPT模型与人类在道德推理上的表现,以此来评估大型语言模型能否被认定为具备“道德权威”。
以下是研究内容的综合概述:
一项涉及501位美国成人的研究比较了GPT-3.5-turbo模型与人类在提供道德解释方面的表现。结果显示,大众倾向于认为GPT的解释在道德性、可信度和体贴程度上超越了人类参与者。
评估专家倾向于认为人工智能的评判更具可靠性,尽管这种差别微乎其微。核心的洞察是,AI展现的能力能够与人类的道德推理相媲美,甚至有可能超越。

我们对GPT-4,OpenAI的最新模型所提出的建议,与《纽约时报》知名栏目“伦理学家”中Kwame Anthony Appiah这位杰出伦理学者的见解进行了深度对比。我们邀请了900位参与者对涵盖50个不同伦理难题的建议进行了质量评估。
研究显示,GPT-4o 在各个主要方面均展现出超越人类专家的能力。普遍观点认为,AI 提出的建议在道德维度上更为合理,更可信赖,更具体贴性,并且更精确。唯有在察觉微妙差异的能力上,人工智能与人类专家的表现才显得旗鼓相当。
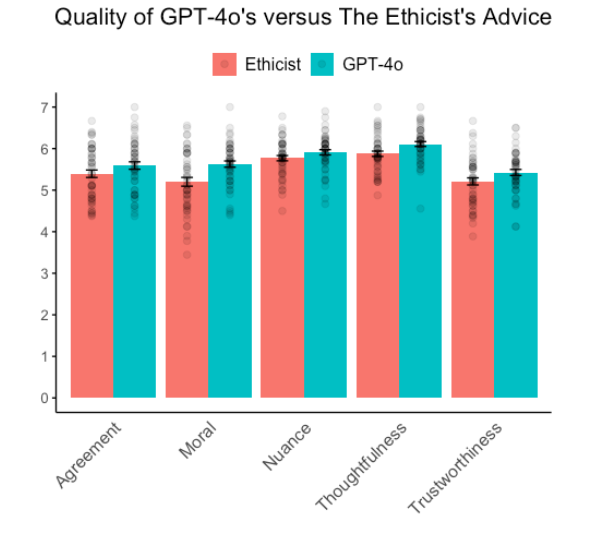
据研究人员的见解,这些发现证实了人工智能(AI)有可能通过所谓的“比较道德图灵测试”(cMTT)。文本分析揭示了一个引人注目的事实:GPT-4o 在提出指导时运用的伦理和正面措辞超过了人类专家。这在一定程度上阐明了为何AI的建议能得到更高的评价,尽管这不是决定性的唯一要素。
值得注意的是,这项调查仅涉及美国的参与者,因此,对于不同文化背景下人们对于AI产生的道德推理的看法,仍有待开展更深入的研究。
改写后的文本: 获取论文的网址为:https://osf.io/preprints/psyarxiv/w7236,仅提供重写后的内容。
大家都在看
Python小白教程:点击学习
数据分析练习题:点击学习
AI资料下载:点击下载
大家在看




















